Rich Lederer • Baseball Beat
Patrick Sullivan • Change-Up
Jeremy Greenhouse • Touching Bases
Dave Allen • F/X Visualizations
Sky Andrecheck • Behind the Scoreboard
Marc Hulet • Around the Minors
Al Doyle • Past Times
Retired Uniforms:
Bryan Smith • WTNY
Joe Sheehan • Command Post
Jeff Albert • The Batter's Eye
RSS Feed
Home
*Examining the Past, Present, and Future*
Lineup Card
Recent Entries
» Putting Together a Reality Team
» Historical Hall of Fame Vote Comparisons: 2012
» An All-Christmas Team
» The New-Look Angels
» John Denny: The Forgotten Cy Young Award Winner
» Money Isn't Everything
» What Would It Take to Hit .400 in the 21st Century?
» Halos Heaven
» Brandon McCarthy's Breakout Season
» Link-o-Rama
» Historical Hall of Fame Vote Comparisons: 2012
» An All-Christmas Team
» The New-Look Angels
» John Denny: The Forgotten Cy Young Award Winner
» Money Isn't Everything
» What Would It Take to Hit .400 in the 21st Century?
» Halos Heaven
» Brandon McCarthy's Breakout Season
» Link-o-Rama
Best of Baseball Beat
Abstracts From the Abstracts
1977 Baseball Abstract
1978 Baseball Abstract
1979 Baseball Abstract
1980 Baseball Abstract
1981 Baseball Abstract
1982 Baseball Abstract
1983 Baseball Abstract
1984 Baseball Abstract
1985 Baseball Abstract
1986 Baseball Abstract
1987 Baseball Abstract
1988 Baseball Abstract
1978 Baseball Abstract
1979 Baseball Abstract
1980 Baseball Abstract
1981 Baseball Abstract
1982 Baseball Abstract
1983 Baseball Abstract
1984 Baseball Abstract
1985 Baseball Abstract
1986 Baseball Abstract
1987 Baseball Abstract
1988 Baseball Abstract
Bert Blyleven Series
Meeting Up and Hanging Out with Bert
The Results Are In And...
Aficionado Heavily Invested in Blyleven
Latest on Blyleven's Chances for the HOF
The Internet Zealot Responds
400 Down and 5 to Go...
Bert Be Home By Eleven?
Blyleven's Forgotten Season (1973)
HeyMan, Your Comments Don't Hold Water
The Waiting is the Hardest Part
Another Addition to the Blyleven Series
Search for the Truth
As Dominant as His HOF Contemporaries
Listen, Buster
A Larger Step for Blyleven
Answering the Naysayers (Part Two)
Another Small Step for Blyleven
Q&A: Blyleven on the Twins
The Majority Rules, Right?
It's All Dutch to Some
The Hall of Fame Case for Bert Blyleven
Q&A: Blyleven on Felix Hernandez
Clemens Rocketing Up Charts
Poz: An Interview With a KC Star
A HOF Chat with Tracy Ringolsby
Up Close and Personal
A Peek Into the Mind of a HOF Voter
Answering the Naysayers
It's That Time of the Year (Again)
"If Cooperstown is Calling..."
The Bert Alert
One Small Step for Blyleven...
Only the Lonely
The Results Are In And...
Aficionado Heavily Invested in Blyleven
Latest on Blyleven's Chances for the HOF
The Internet Zealot Responds
400 Down and 5 to Go...
Bert Be Home By Eleven?
Blyleven's Forgotten Season (1973)
HeyMan, Your Comments Don't Hold Water
The Waiting is the Hardest Part
Another Addition to the Blyleven Series
Search for the Truth
As Dominant as His HOF Contemporaries
Listen, Buster
A Larger Step for Blyleven
Answering the Naysayers (Part Two)
Another Small Step for Blyleven
Q&A: Blyleven on the Twins
The Majority Rules, Right?
It's All Dutch to Some
The Hall of Fame Case for Bert Blyleven
Q&A: Blyleven on Felix Hernandez
Clemens Rocketing Up Charts
Poz: An Interview With a KC Star
A HOF Chat with Tracy Ringolsby
Up Close and Personal
A Peek Into the Mind of a HOF Voter
Answering the Naysayers
It's That Time of the Year (Again)
"If Cooperstown is Calling..."
The Bert Alert
One Small Step for Blyleven...
Only the Lonely
Exclusive Interviews
Lee Sinins
Alex Belth
David Pinto
Will Carroll
Mike Carminati
Aaron Gleeman
Joe Sheehan
Jay Jaffe
Jeff Peek
Tracy Ringolsby
Joe Posnanski
Bill James Part I, II, III
Jon Lalonde
Chuck Tiffany
Dayn Perry
Fay Vincent
Nate Silver
Alex Belth
David Pinto
Will Carroll
Mike Carminati
Aaron Gleeman
Joe Sheehan
Jay Jaffe
Jeff Peek
Tracy Ringolsby
Joe Posnanski
Bill James Part I, II, III
Jon Lalonde
Chuck Tiffany
Dayn Perry
Fay Vincent
Nate Silver
Bullpen
Rich Lederer
The Odd Couple (with Alex Belth)
The MostUnder Over Underrated Player in Baseball (with Brian Gunn)
Three Wise Men (roundtable by Alex Belth)
Infrequently Asked Questions (interview with Matt Welch)
Interview (Orioles Think Tank)
Bernie and the Yanks (Bronx Banter)
Hope and Faith: How the LAA Win the World Series (Baseball Prospectus)
NL West (The Soul of Baseball)
Greatest Living Hitter? (Sports Illustrated)
Roundtable: 2008 HOF Ballot (Armchair GM)
The Most
Three Wise Men (roundtable by Alex Belth)
Infrequently Asked Questions (interview with Matt Welch)
Interview (Orioles Think Tank)
Bernie and the Yanks (Bronx Banter)
Hope and Faith: How the LAA Win the World Series (Baseball Prospectus)
NL West (The Soul of Baseball)
Greatest Living Hitter? (Sports Illustrated)
Roundtable: 2008 HOF Ballot (Armchair GM)
Patrick Sullivan
Designated Hitters
David Bromberg (Q&A: John Denny)
Mark Armour (H. Killebrew and Versatility)
Joe Lederer (Soundtrack of a Prospect)
David Bromberg (Clemente's Autograph)
David Bromberg (Woody Fryman)
D. Baumstein (WAR Against Age: Pitchers)
Doug Baumstein (The WAR Against Age)
Doug Baumstein (A Lifetime on the Road)
John Fraser (Pick Six)
Mark Armour (How to Score More Runs?)
Bill Parker (What Opening Day Tells Us)
Stan Opdyke (Pat Rispole)
Chris Jaffe (Evaluating Baseball's Mgrs)
Stan Opdyke (Baseball Radio in NYC, 1953)
A. Nathan (Performance of Baseball Bats)
Michael Weddell (Edgar Martinez/HOF)
Jon Weisman (100 Things Dodgers Fans...)
Stan Opdyke (Connie Mack and Vin Scully)
Eric Walker (Evaluating Run Production)
Brent Mayne (The Intangibles of Catching)
Chris Moore (Best Fastballs in Baseball)
Dave Baldwin (The Batter’s Brain)
Shawn Haviland (Ivy League to MLB)
Larry Granillo (Walking Off)
Rob Iracane (Solo HR Won't Break You)
Tommy Bennett (Charm of AM Radio)
Harry Pavlidis (Johan Santana's Fast Start)
John Walsh (WAR and Remembrance)
Eric Walker (Precisely Inaccurate)
Bob Timmermann (As They See 'Em)
Geoff Young (Unicycles and Delusions)
Baseball Analysis at Tufts (Groundballers)
Baseball Analysis at Tufts (GB Out Rates)
G. Rybarczyk ('09 Hit Tracker Projections)
Joe Lederer (Curt Schilling/HoF)
Conor Gallagher (Hall of Fallacies)
Chris Green (Jim Rice, HoF, the Numbers)
Shawn Hoffman (Baseball's Bear Mkt?)
Paul Anthony (Manny Syndrome)
Ross Roley (World Series Odds)
B. Timmermann (Catcher's Interference)
R.J. Anderson (Waiting the Hardest Part)
Maury Brown (Cubs, MLB, and Cuban...)
Myron Logan (Dee-Fense, Dee-Fense)
Craig Calcaterra (Frivolity, Part I, Part II)
Chad Finn (Ode to Baseball Cards)
David Cameron (Mariners Foibles)
Chris Dial (Chipper Jones)
Pat Lederer (Memory Lane)
David Appelman (Clutch Pitching)
Bob Rittner (DH)
Jonathan Mayo (Roger Clemens)
Lisa Winston (My Son-in-Law...)
Russ McQueen (The Yellow Hammer)
Bob Rittner (I'm OK, You're OK)
Mark Armour (In Defense of the HOF)
Pat Jordan (Friends)
Dan Levitt (Analysis of Terry Ryan)
Doug Baumstein (Trading Econ 101)
Ross Roley (Runner's Reluctance II)
Ross Roley (Runner's Reluctance I)
Mark Armour (No-Longer Lovable Sox)
Bruce Regal (Stealthy and Wise)
Brian Gunn (Roid Monster)
Current/McEvoy (Value of the SB)
John Rickert (Sinister Thefts)
Nate Silver (Sabermetrics)
David Vincent (Home Run Production)
Joe P. Sheehan (Enhanced Gameday II)
Mark Armour (An Ode to Sport)
David Gassko (All-Time Worm Burners)
Joe P. Sheehan (Enhanced Gameday)
John Walsh (When Titans Clash)
Fox/Williams (Quantifying Coaches II)
Fox/Williams (Quantifying Coaches I)
Jacob Luft (Bull Durham Rant)
Chad Finn (Strat-O-Matic)
Lisa Winston (Rotisserie Baseball)
Dave Studeman (Baseball Stats)
Steve Treder (Roger Craig)
Marc Normandin (Jeff Bagwell)
D. Appelman (Expanding Strike Zone)
Jeff Sackmann (Worst MiL Defenders)
Jeff Sackmann (Best MiL Defenders)
Maxwell Kates (Van Lingle Mungo)
David Appelman (Pitch Location)
Kent Bonham (Danny Ray Herrera)
Glenn Stout (Two Baseball Poems)
Bruce Regal (The Challenge Round)
Mark Lamster (Barry & Ty)
Geoff Young (NL West)
Tom Lederer (The Ryan Express)
Brian Erts (Great Leap Forward)
David Pinto (Parity and the N.L.)
Jacob Luft (Fathers and Daughters)
Jamey Newberg (Pete's Sake)
Jeff Albert (A. Jones Swing Analysis)
Jeff Albert (A-Rod Swing Analysis)
Keith Law (Death, Taxes, and Waivers)
Peter Abraham (Tales of Torre Tales)
Larry Borowsky (Let 'er Rip II)
Dan Levitt (Empirical Analysis of Bunting)
Jonah Keri (If I Met Warren Cromartie...)
Bob Klapisch (War Stories)
Bob Timmermann (John F. Kennedy HS)
Kent Bonham (Aluminum Adjustments)
Al Doyle (More Than Superstars)
Ross Roley (Instant Replay)
David Vincent (Barry Bonds Homers)
Chad Finn (Our Favorite Obscurities)
Bill Deane (1979 NL MVP)
Mark Armour (Rise/Fall of Artificial Turf)
Jeff Angus (Wally Moon Camp)
David Berri (Money and Baseball)
Larry Borowsky (Baseball w/o the #s)
Derek Zumsteg (The Irrational Market)
David Regan (Free Agent Contracts)
Peter Schmuck (Steroids and the HOF)
David Appelman (Pitchers, Pitch by Pitch)
Dan Fox (Swinging, Taking, Fouling, Etc)
Patrick Sullivan (Study of NYY CF/BOS LF)
Will Leitch (Baseball Journalism)
Jeff Sullivan (Pitcher Release Points)
Steve Treder ('69-'70 Giants)
Maury Brown (Charlie Finley)
John Brattain (Bob Johnson)
Bob Klapisch (The Case for Bert Blyleven)
Jeff Peek (Pride and Prejudice)
Dayn Perry (Bert and Warren)
Rob Neyer (If Don Sutton Was Great...)
Lisa Winston (Minor League Memories)
Alex Belth (Otis Redding Was Right)
David Cameron (Long Live the King)
Jeff Angus (Baserunning Study)
Bert Blyleven (Baseball Playoffs)
Boyd Nation (Not a Prospect List)
James Click (Batters-Baserunners Study)
Jeff Shaw (Why I Love Baseball)
David Gassko (BIP/BFP Fielding Study)
Jay Jaffe (Milwaukee Sausage Race)
Jamey Newberg (Remember When)
Bob Klapisch (Press Box to the Mound)
Dan Levitt (Predictive Value of BB)
David Vincent (Official Scorer)
Jon Weisman (Rick Monday)
Larry Borowsky (Let 'er Rip)
Will Carroll (Fictional Short Story)
Bob Timmermann (Japanese Baseball)
Cyril Morong (Best Pitching Seasons)
Sean Forman (Monte Carlo Win-Loss)
Brian Gunn (My Little Blue Book)
Joe Lederer (My Dad and Baseball)
Bill Deane (Bob Gibson, 1968)
Mark Armour (1977 Yankees)
Darren Viola (Retrosheet)
David Pinto (RFK)
Dayn Perry (Brave Heart)
Matt Welch (Dave Hansen)
Kevin Kernan (Jack McKeon)
Tom Lederer (Dodgers Road Trip)
Steve Lombardi (Slider)
Studes (Picturing Baseball)
Mike Carminati (Luck of the Drawl)
Eric Neel (Vin Scully)
J.C. Bradbury (Leo Mazzone)
John Sickels (Bill James)
Mark Armour (H. Killebrew and Versatility)
Joe Lederer (Soundtrack of a Prospect)
David Bromberg (Clemente's Autograph)
David Bromberg (Woody Fryman)
D. Baumstein (WAR Against Age: Pitchers)
Doug Baumstein (The WAR Against Age)
Doug Baumstein (A Lifetime on the Road)
John Fraser (Pick Six)
Mark Armour (How to Score More Runs?)
Bill Parker (What Opening Day Tells Us)
Stan Opdyke (Pat Rispole)
Chris Jaffe (Evaluating Baseball's Mgrs)
Stan Opdyke (Baseball Radio in NYC, 1953)
A. Nathan (Performance of Baseball Bats)
Michael Weddell (Edgar Martinez/HOF)
Jon Weisman (100 Things Dodgers Fans...)
Stan Opdyke (Connie Mack and Vin Scully)
Eric Walker (Evaluating Run Production)
Brent Mayne (The Intangibles of Catching)
Chris Moore (Best Fastballs in Baseball)
Dave Baldwin (The Batter’s Brain)
Shawn Haviland (Ivy League to MLB)
Larry Granillo (Walking Off)
Rob Iracane (Solo HR Won't Break You)
Tommy Bennett (Charm of AM Radio)
Harry Pavlidis (Johan Santana's Fast Start)
John Walsh (WAR and Remembrance)
Eric Walker (Precisely Inaccurate)
Bob Timmermann (As They See 'Em)
Geoff Young (Unicycles and Delusions)
Baseball Analysis at Tufts (Groundballers)
Baseball Analysis at Tufts (GB Out Rates)
G. Rybarczyk ('09 Hit Tracker Projections)
Joe Lederer (Curt Schilling/HoF)
Conor Gallagher (Hall of Fallacies)
Chris Green (Jim Rice, HoF, the Numbers)
Shawn Hoffman (Baseball's Bear Mkt?)
Paul Anthony (Manny Syndrome)
Ross Roley (World Series Odds)
B. Timmermann (Catcher's Interference)
R.J. Anderson (Waiting the Hardest Part)
Maury Brown (Cubs, MLB, and Cuban...)
Myron Logan (Dee-Fense, Dee-Fense)
Craig Calcaterra (Frivolity, Part I, Part II)
Chad Finn (Ode to Baseball Cards)
David Cameron (Mariners Foibles)
Chris Dial (Chipper Jones)
Pat Lederer (Memory Lane)
David Appelman (Clutch Pitching)
Bob Rittner (DH)
Jonathan Mayo (Roger Clemens)
Lisa Winston (My Son-in-Law...)
Russ McQueen (The Yellow Hammer)
Bob Rittner (I'm OK, You're OK)
Mark Armour (In Defense of the HOF)
Pat Jordan (Friends)
Dan Levitt (Analysis of Terry Ryan)
Doug Baumstein (Trading Econ 101)
Ross Roley (Runner's Reluctance II)
Ross Roley (Runner's Reluctance I)
Mark Armour (No-Longer Lovable Sox)
Bruce Regal (Stealthy and Wise)
Brian Gunn (Roid Monster)
Current/McEvoy (Value of the SB)
John Rickert (Sinister Thefts)
Nate Silver (Sabermetrics)
David Vincent (Home Run Production)
Joe P. Sheehan (Enhanced Gameday II)
Mark Armour (An Ode to Sport)
David Gassko (All-Time Worm Burners)
Joe P. Sheehan (Enhanced Gameday)
John Walsh (When Titans Clash)
Fox/Williams (Quantifying Coaches II)
Fox/Williams (Quantifying Coaches I)
Jacob Luft (Bull Durham Rant)
Chad Finn (Strat-O-Matic)
Lisa Winston (Rotisserie Baseball)
Dave Studeman (Baseball Stats)
Steve Treder (Roger Craig)
Marc Normandin (Jeff Bagwell)
D. Appelman (Expanding Strike Zone)
Jeff Sackmann (Worst MiL Defenders)
Jeff Sackmann (Best MiL Defenders)
Maxwell Kates (Van Lingle Mungo)
David Appelman (Pitch Location)
Kent Bonham (Danny Ray Herrera)
Glenn Stout (Two Baseball Poems)
Bruce Regal (The Challenge Round)
Mark Lamster (Barry & Ty)
Geoff Young (NL West)
Tom Lederer (The Ryan Express)
Brian Erts (Great Leap Forward)
David Pinto (Parity and the N.L.)
Jacob Luft (Fathers and Daughters)
Jamey Newberg (Pete's Sake)
Jeff Albert (A. Jones Swing Analysis)
Jeff Albert (A-Rod Swing Analysis)
Keith Law (Death, Taxes, and Waivers)
Peter Abraham (Tales of Torre Tales)
Larry Borowsky (Let 'er Rip II)
Dan Levitt (Empirical Analysis of Bunting)
Jonah Keri (If I Met Warren Cromartie...)
Bob Klapisch (War Stories)
Bob Timmermann (John F. Kennedy HS)
Kent Bonham (Aluminum Adjustments)
Al Doyle (More Than Superstars)
Ross Roley (Instant Replay)
David Vincent (Barry Bonds Homers)
Chad Finn (Our Favorite Obscurities)
Bill Deane (1979 NL MVP)
Mark Armour (Rise/Fall of Artificial Turf)
Jeff Angus (Wally Moon Camp)
David Berri (Money and Baseball)
Larry Borowsky (Baseball w/o the #s)
Derek Zumsteg (The Irrational Market)
David Regan (Free Agent Contracts)
Peter Schmuck (Steroids and the HOF)
David Appelman (Pitchers, Pitch by Pitch)
Dan Fox (Swinging, Taking, Fouling, Etc)
Patrick Sullivan (Study of NYY CF/BOS LF)
Will Leitch (Baseball Journalism)
Jeff Sullivan (Pitcher Release Points)
Steve Treder ('69-'70 Giants)
Maury Brown (Charlie Finley)
John Brattain (Bob Johnson)
Bob Klapisch (The Case for Bert Blyleven)
Jeff Peek (Pride and Prejudice)
Dayn Perry (Bert and Warren)
Rob Neyer (If Don Sutton Was Great...)
Lisa Winston (Minor League Memories)
Alex Belth (Otis Redding Was Right)
David Cameron (Long Live the King)
Jeff Angus (Baserunning Study)
Bert Blyleven (Baseball Playoffs)
Boyd Nation (Not a Prospect List)
James Click (Batters-Baserunners Study)
Jeff Shaw (Why I Love Baseball)
David Gassko (BIP/BFP Fielding Study)
Jay Jaffe (Milwaukee Sausage Race)
Jamey Newberg (Remember When)
Bob Klapisch (Press Box to the Mound)
Dan Levitt (Predictive Value of BB)
David Vincent (Official Scorer)
Jon Weisman (Rick Monday)
Larry Borowsky (Let 'er Rip)
Will Carroll (Fictional Short Story)
Bob Timmermann (Japanese Baseball)
Cyril Morong (Best Pitching Seasons)
Sean Forman (Monte Carlo Win-Loss)
Brian Gunn (My Little Blue Book)
Joe Lederer (My Dad and Baseball)
Bill Deane (Bob Gibson, 1968)
Mark Armour (1977 Yankees)
Darren Viola (Retrosheet)
David Pinto (RFK)
Dayn Perry (Brave Heart)
Matt Welch (Dave Hansen)
Kevin Kernan (Jack McKeon)
Tom Lederer (Dodgers Road Trip)
Steve Lombardi (Slider)
Studes (Picturing Baseball)
Mike Carminati (Luck of the Drawl)
Eric Neel (Vin Scully)
J.C. Bradbury (Leo Mazzone)
John Sickels (Bill James)
Search Baseball Analysts
Archives
By Category:
Around the Majors Content Only
Around the Minors Content Only
Baseball Beat Content Only
Baseball Beat/Change-Up Content Only
Baseball Beat/WTNY Content Only
Behind the Scoreboard Content Only
Change-Up Content Only
Change-Up/Around the Majors Content Only
Command Post Content Only
Crunching the Numbers Content Only
Designated Hitter Content Only
F/X Visualizations Content Only
Past Times Content Only
Saber Talk Content Only
The Batter's Eye Content Only
Touching Bases Content Only
Weekend Blog Content Only
WTNY Content Only
Around the Minors Content Only
Baseball Beat Content Only
Baseball Beat/Change-Up Content Only
Baseball Beat/WTNY Content Only
Behind the Scoreboard Content Only
Change-Up Content Only
Change-Up/Around the Majors Content Only
Command Post Content Only
Crunching the Numbers Content Only
Designated Hitter Content Only
F/X Visualizations Content Only
Past Times Content Only
Saber Talk Content Only
The Batter's Eye Content Only
Touching Bases Content Only
Weekend Blog Content Only
WTNY Content Only
By Month:
February 2012
January 2012
December 2011
October 2011
September 2011
August 2011
July 2011
June 2011
May 2011
April 2011
March 2011
February 2011
January 2011
December 2010
November 2010
October 2010
September 2010
August 2010
July 2010
June 2010
May 2010
April 2010
March 2010
February 2010
January 2010
December 2009
November 2009
October 2009
September 2009
August 2009
July 2009
June 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
October 2008
September 2008
August 2008
July 2008
June 2008
May 2008
April 2008
March 2008
February 2008
January 2008
December 2007
November 2007
October 2007
September 2007
August 2007
July 2007
June 2007
May 2007
April 2007
March 2007
February 2007
January 2007
December 2006
November 2006
October 2006
September 2006
August 2006
July 2006
June 2006
May 2006
April 2006
March 2006
February 2006
January 2006
December 2005
November 2005
October 2005
September 2005
August 2005
July 2005
June 2005
May 2005
April 2005
March 2005
February 2005
January 2005
December 2004
November 2004
October 2004
September 2004
August 2004
July 2004
June 2004
May 2004
April 2004
March 2004
February 2004
January 2004
December 2003
November 2003
October 2003
September 2003
August 2003
July 2003
June 2003
January 2012
December 2011
October 2011
September 2011
August 2011
July 2011
June 2011
May 2011
April 2011
March 2011
February 2011
January 2011
December 2010
November 2010
October 2010
September 2010
August 2010
July 2010
June 2010
May 2010
April 2010
March 2010
February 2010
January 2010
December 2009
November 2009
October 2009
September 2009
August 2009
July 2009
June 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
October 2008
September 2008
August 2008
July 2008
June 2008
May 2008
April 2008
March 2008
February 2008
January 2008
December 2007
November 2007
October 2007
September 2007
August 2007
July 2007
June 2007
May 2007
April 2007
March 2007
February 2007
January 2007
December 2006
November 2006
October 2006
September 2006
August 2006
July 2006
June 2006
May 2006
April 2006
March 2006
February 2006
January 2006
December 2005
November 2005
October 2005
September 2005
August 2005
July 2005
June 2005
May 2005
April 2005
March 2005
February 2005
January 2005
December 2004
November 2004
October 2004
September 2004
August 2004
July 2004
June 2004
May 2004
April 2004
March 2004
February 2004
January 2004
December 2003
November 2003
October 2003
September 2003
August 2003
July 2003
June 2003
Reference
Organizational Stats
Arizona Diamondbacks Bat / Pitch
Atlanta Braves Bat / Pitch
Baltimore Orioles Bat / Pitch
Boston Red Sox Bat / Pitch
Chicago Cubs Bat / Pitch
Chicago White Sox Bat / Pitch
Cincinnati Reds Bat / Pitch
Cleveland Indians Bat / Pitch
Colorado Rockies Bat / Pitch
Detroit Tigers Bat / Pitch
Florida Marlins Bat / Pitch
Houston Astros Bat / Pitch
Kansas City Royals Bat / Pitch
Los Angeles Angels Bat / Pitch
Los Angeles Dodgers Bat / Pitch
Milwaukee Brewers Bat / Pitch
Minnesota Twins Bat / Pitch
New York Mets Bat / Pitch
New York Yankees Bat / Pitch
Oakland Athletics Bat / Pitch
Philadelphia Phillies Bat / Pitch
Pittsburgh Pirates Bat / Pitch
St. Louis Cardinals Bat / Pitch
San Diego Padres Bat / Pitch
San Francisco Giants Bat / Pitch
Seattle Mariners Bat / Pitch
Tampa Bay Devil Rays Bat / Pitch
Texas Rangers Bat / Pitch
Toronto Blue Jays Bat / Pitch
Washington Nationals Bat / Pitch
Atlanta Braves Bat / Pitch
Baltimore Orioles Bat / Pitch
Boston Red Sox Bat / Pitch
Chicago Cubs Bat / Pitch
Chicago White Sox Bat / Pitch
Cincinnati Reds Bat / Pitch
Cleveland Indians Bat / Pitch
Colorado Rockies Bat / Pitch
Detroit Tigers Bat / Pitch
Florida Marlins Bat / Pitch
Houston Astros Bat / Pitch
Kansas City Royals Bat / Pitch
Los Angeles Angels Bat / Pitch
Los Angeles Dodgers Bat / Pitch
Milwaukee Brewers Bat / Pitch
Minnesota Twins Bat / Pitch
New York Mets Bat / Pitch
New York Yankees Bat / Pitch
Oakland Athletics Bat / Pitch
Philadelphia Phillies Bat / Pitch
Pittsburgh Pirates Bat / Pitch
St. Louis Cardinals Bat / Pitch
San Diego Padres Bat / Pitch
San Francisco Giants Bat / Pitch
Seattle Mariners Bat / Pitch
Tampa Bay Devil Rays Bat / Pitch
Texas Rangers Bat / Pitch
Toronto Blue Jays Bat / Pitch
Washington Nationals Bat / Pitch
All-Star Links
Official Websites
News and Notes
Baseball News Blog
Baseball Newstand
ESPN Baseball
Fox Sports Baseball
Pro Sports Daily
Roto World
The Roto Times
USA Today Baseball
Baseball Newstand
ESPN Baseball
Fox Sports Baseball
Pro Sports Daily
Roto World
The Roto Times
USA Today Baseball
Reference and Analysis
Baseball Almanac
Baseball America
Baseball Archive
Baseball Contracts
Baseball Cube
Baseball Graphs
Baseball Library
Baseball Musings Player Database
Baseball Page
Baseball Primer
Baseball Prospectus
Baseball Reference
Baseball Statistics
Baseball Truth
Boxscore Central
Diamond Mind Baseball
Doug's Stats
FanGraphs
Fast Balls (pitchfx catalog)
Hardball Dollars
Hardball Times
Hit Tracker
Retrosheet
Rotobase/Rotoblog
Stat Corner
STATS
Tango on Baseball
Yahoo Sports MLB
Baseball America
Baseball Archive
Baseball Contracts
Baseball Cube
Baseball Graphs
Baseball Library
Baseball Musings Player Database
Baseball Page
Baseball Primer
Baseball Prospectus
Baseball Reference
Baseball Statistics
Baseball Truth
Boxscore Central
Diamond Mind Baseball
Doug's Stats
FanGraphs
Fast Balls (pitchfx catalog)
Hardball Dollars
Hardball Times
Hit Tracker
Retrosheet
Rotobase/Rotoblog
Stat Corner
STATS
Tango on Baseball
Yahoo Sports MLB
Web Gems
Bill James Primer
Sabermetric Manifesto (Grabiner)
Pitching and Defense (McCracken)
Pitching and Defense (Tippett)
Transactions Primer (Neyer)
Baseball Stats (Batter's Box)
Prospect Report (Cameron)
Pitcher Workloads (Sheehan)
Goodbye to Old Baseball Ideas (Rickey)
Sabermetric Manifesto (Grabiner)
Pitching and Defense (McCracken)
Pitching and Defense (Tippett)
Transactions Primer (Neyer)
Baseball Stats (Batter's Box)
Prospect Report (Cameron)
Pitcher Workloads (Sheehan)
Goodbye to Old Baseball Ideas (Rickey)
Columnists
Baseball Blogs
Around the Majors
Athletics Nation
Baseball Crank
Baseball Musings
Baseball-Reference Blog
Batter's Box
Big League Stew
Bronx Banter
Catfish Stew
Cub Town
Dan Agonistes
Dodger Thoughts
DRays Bay
Ducksnorts
Futility Infielder
Halos Heaven
Inside the Rockies
It Might Be Dangerous
Knuckle Curve
LoHud Yankees Blog
Lookout Landing
Management by Baseball
Metaforian
Metsgeek
Mike's Baseball Rants
Only Baseball Matters
Redbird Nation
Red Reporter
Sabernomics (Braves)
Seth Speaks
ShysterBall
6-4-2 (Angels/Dodgers)
The Book
TheCubdom
The Cutting Edge
The House That Dewey Built
The View From The Bleachers
Tiger Blog
U.S.S. Mariner
Viva El Birdos
Where's Kernan
Athletics Nation
Baseball Crank
Baseball Musings
Baseball-Reference Blog
Batter's Box
Big League Stew
Bronx Banter
Catfish Stew
Cub Town
Dan Agonistes
Dodger Thoughts
DRays Bay
Ducksnorts
Futility Infielder
Halos Heaven
Inside the Rockies
It Might Be Dangerous
Knuckle Curve
LoHud Yankees Blog
Lookout Landing
Management by Baseball
Metaforian
Metsgeek
Mike's Baseball Rants
Only Baseball Matters
Redbird Nation
Red Reporter
Sabernomics (Braves)
Seth Speaks
ShysterBall
6-4-2 (Angels/Dodgers)
The Book
TheCubdom
The Cutting Edge
The House That Dewey Built
The View From The Bleachers
Tiger Blog
U.S.S. Mariner
Viva El Birdos
Where's Kernan
Minor Leagues
Arizona Fall League
BA Player Finder
Cal Leaguers
Jamey Newberg
JDM's Scoresheet Baseball
Minor League Baseball
Minor League Park Factors
Minor League Splits
No Pepper
Sickels' Minor League Ball
Warm October Nights
BA Player Finder
Cal Leaguers
Jamey Newberg
JDM's Scoresheet Baseball
Minor League Baseball
Minor League Park Factors
Minor League Splits
No Pepper
Sickels' Minor League Ball
Warm October Nights
Amateur
Boyd's World (College)
Cape Cod Baseball League
College Baseball Blog
College Baseball Insider
Collegiate Baseball Newspaper
College Splits
College Splits Blog
Dirtbags Baseball (Long Beach State)
NCAA Baseball
NCBWA
Team One Baseball (High School)
Texas A&M & Baseball
Cape Cod Baseball League
College Baseball Blog
College Baseball Insider
Collegiate Baseball Newspaper
College Splits
College Splits Blog
Dirtbags Baseball (Long Beach State)
NCAA Baseball
NCBWA
Team One Baseball (High School)
Texas A&M & Baseball
Historical
Cuban Baseball
House of David
Jim "Mudcat" Grant's Web Page
Negro League Baseball Players Assoc
Negro Leagues Baseball Museum
1919 Black Sox
Pacific Coast League
Philadelphia Athletics Historical Society
Shoeless Joe Jackson Society
SABR-L Archives
Walter O'Malley
House of David
Jim "Mudcat" Grant's Web Page
Negro League Baseball Players Assoc
Negro Leagues Baseball Museum
1919 Black Sox
Pacific Coast League
Philadelphia Athletics Historical Society
Shoeless Joe Jackson Society
SABR-L Archives
Walter O'Malley
Miscellaneous
Forums
Credits
Ticket Center
Tickets to Baseball -
Premium Red Sox Tickets - Tickets to Marlins Games - Cardinals Game Tickets - NY Yankee Tickets - Tickets Oakland Athletics - Dallas Cowboys Tickets - Arizona Cardinals Tickets - Tickets Seattle Seahawks - Buffalo Bills Tickets Online - Tickets to Dolphins Football
Buy Boston Red Sox tickets,
Philadelphia Phillies tix,
NY Yankees tickets,
NY Mets tickets, and
MLB All Star game tickets at ABC tickets
Not sure where to find the best online sportsbooks? Start your search with PlayersJet.
Get deals at SportsMemorabilia.com on baseball apparel, including Phillies jerseys and more for adults and children.
Shop the largest selection baseball equipment on sale at Sports Unlimited. Check out tons of baseball gloves, youth baseball gloves and catchers gear from Rawlings, Wilson, Nike & Under Armour.
2011 Draft Order
Courtesy of Baseball America
First-Round:
1. Pirates (57-105) 2. Mariners (61-101) 3. Diamondbacks (65-97) 4. Orioles (66-96) 5. Royals (67-95) 6. Nationals (69-93) 7. Diamondbacks (for B. Loux) 8. Indians (69-93) 9. Cubs (75-87) 10. Padres (for Karsten Whitson) 11. Astros (76-86) 12. Brewers (77-85) 13. Mets (79-83) 14. Marlins (80-82) 15. Brewers (for Dylan Covey) 16. Dodgers (80-82) 17. Angels (80-82) 18. Athletics (81-81) 19. Red Sox (from DET for Martinez) 20. Rockies (83-79) 21. Blue Jays (85-77) 22. Cardinals (86-76) 23. Nationals (from CWS for Dunn) 24. Rays (from BOS for Crawford) 25. Padres (90-72) 26. Red Sox (from TEX for Beltre) 27. Reds (91-71) 28. Braves (91-71) 29. Giants (92-70) 30. Twins (94-68) 31. Rays (from NYY for Soriano) 32. Rays (96-66) 33. Rangers (from PHI for Lee)Supplemental First Round:
34. Nationals (Dunn) 35. Blue Jays (Downs) 36. Red Sox (Martinez) 37. Rangers (Lee) 38. Rays (Crawford) 39. Phillies (Werth) 40. Red Sox (Beltre) 41. Rays (Soriano) 42. Rays (Balfour) 43. Diamondbacks (LaRoche) 44. Mets (Feliciano) 45. Rockies (Dotel) 46. Blue Jays (Buck) 47. White Sox (Putz) 48. Padres (Garland) 49. Giants (Uribe) 50. Twins (Hudson) 51. Yankees (Vazquez) 52. Rays (Benoit) 53. Blue Jays (Olivo) 54. Padres (Torrealba) 55. Twins (Crain) 56. Rays (Choate) 57. Blue Jays (Gregg) 58. Padres (Correia) 59. Rays (Hawpe)
| Behind the Scoreboard | August 11, 2009 |
How Best to Measure a Team's True Talent
One of the first sabermetric principles that many people learn about is how a team's winning percentage can be predicted by the number of runs scored and allowed. This Pythagorean winning percentage takes the following form: WPCT= RS^1.81/(RS^1.81 + RA^1.81). It was introduced by Bill James and is purported to detect whether a team is underperforming or playing over their heads and is billed as a better guide of a team's true talent. This concept has reached so far into the mainstream that it is even included in the MLB.com standings.
Furthermore, sabermetricians can dig deeper into a team's performance, and estimate the amount of runs that a team is expected to score or allow, based on the components of hits, walks, and outs tallied by a team or its opponents. Applying these run values to the Pythagorean winning percentage method can supposedly provide an even better guide to a team's true talent level, since even more of the variability is removed from the equation. Talking to some sabermetricians leaves the impression that W-L record should be thrown out all together and only these deeper metrics should be examined.
Hail Pythagoras?
But while some claim that the Pythagorean winning percentage or its counterparts are a better guide to a team's ability, is this actually so? This concept has been studied before, but here I take another look at it. Which one of these three metrics (WPCT, Pythagorean WPCT, and component Pythagorean WPCT) is best and is there some way to combine all three metrics to get the the best possible estimator of a team's ability?
Using retrosheet data going back to 1960, I obtained the statistics to calculate WPCT, Pythagorean WPCT, and component Pythagorean WPCT (based upon Bill James' Runs Created). I then randomly selected 25% of each team's games and calculated these metrics from these games only. From these 40 or so games, I attempted to predict the team's actual WPCT in the remaining games that were not sampled. How did each of these metrics fare?
Fitting a Model
First, using teams' regular WPCT from the sample 25% of games, we can fit a simple model to predict the teams' WPCT in the other 75% of games. To increase the power of our dataset, we can randomly draw many such 25% samples and average the outcomes. I drew 100 such random samples and ran the results. When doing so, we get the following formula:
Remaining WPCT = .363*(Current WPCT) + .319.
The RMSE of this estimate of WPCT is .0659, meaning that the winning percentage for the remaining games has a fairly wide range of outcomes - no surprise to any baseball fan. Also no surprise is the fact that the teams' WPCT over 25% of its games is regressed to .500 fairly strongly. A team playing .650 baseball over 40 games has an expected true winning percentage of just .555. The RMSE underscores the uncertainty - a 95% confidence interval has the team's true WPCT somewhere between .424 and .686.
But, does this improve at all when using the Pythagorean formula for estimating WPCT from runs scored and runs allowed? The formula for this is following:
Remaining WPCT = .440*(Pythagorean WPCT) + .280.
In this case, the teams' WPCT regresses less strongly - a team with a .650 Pythagorean WPCT has an expected true WPCT of .566 rather than .555. The accuracy is improved, but the RMSE is still .0648, only slightly better than using regular WPCT.
How about for the Component Pythagorean WPCT using Runs Created? The formula is nearly the same as that for the regular Pythagorean WPCT. It performs the best of the three methods, with a RMSE of .0643, though again, the increase in accuracy is small.
So from the above, we see that with 40 games of information, all three methods have similar accuracy, though the Runs Created Pythagorean formula fares best, and real WPCT fares the worst.
Combining All Three Metrics
How about when all three measures are used to try to predict WPCT? Putting all three measures in the model, we get the following formula:
Remaining WPCT = .103*(Current WPCT) + .094*(Pythag WPCT) + .268*(RC WPCT) + .268.
When comparing the three types of estimated WPCT's, real WPCT gets about 20% of the weight, another 20% goes to the Pythagorean WPCT, and the final 60% of the weight goes to the Runs Created Pythagorean formula. Of course, this is all regressed back to the mean as well, so that a team with a .650 WPCT in each of the three metrics would be expected to have a true WPCT of .570. The RMSE of this estimate is of course lower than each of the three measures separately, but is still high at .0638. This compared to .0659 for using WPCT alone.
What can we take from this information? We see that indeed the sabermetricians are right - a team's performance broken down into runs created components is a better gauge of a team's true talent level than just looking at a team's winning percentage alone. However, using all three metrics provides the best estimate of a team's true talent.
Much Ado?
But is all of this worth it? The increase in accuracy when looking at all three metrics is very small. Taking the expected random variability out of the RMSE, using the formula Variability in the Prediction of True Talent = RMSE^2 - Variability of WPCT by Chance, we see that the standard error of our prediction of true talent is .0450 when using the full model, while the standard error is .0479 when using WPCT alone.
This means that a 95% confidence interval around .500 would be (.410,.590) for the full model, while it would be (.404,.596) when using WPCT alone. Is this increase in accuracy really worth all of the trouble? You can make your own judgment, but I think it's fair to say that looking at a team's Pythagorean WPCT or component Runs Created WPCT doesn't necessarily tell you a whole lot more than looking at WPCT alone.
Extensions of the Model
Of course, this discussion has so far only concerned the case where the team has played just 25% of its games. What happens when the result of more of the season is known? Below is a table of model results, showing the coefficients for each metric after 25%, 50%, and 75% of the season is known respectively.
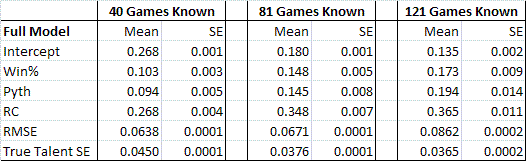
As you can see from the results above, the weights given to each metric remain relatively stable no matter how many games have been played. The WPCT estimated from Runs Created remains the metric with the most weight in the full formula, while the Pythagorean WPCT and real WPCT are about equal in importance. As we approach the 3/4ths mark of the season, we can see that when trying to assess a team based on its performance thus far, about 50% of our estimate should come from the Runs Created measure, and about 25% should be from the team's real WPCT and the team's Pythagorean WPCT respectively. The formula is as follows:
Remaining WPCT = .173*(Current WPCT) + .194*(Pythag WPCT) + .365*(RC WPCT) + .135.
This is slightly more accurate than using WPCT alone, decreasing the SE of the true talent estimate from .0399 under WPCT alone to .0365 by using the full model.
Conclusion
As I said earlier, this increase in accuracy is quite small, so this entire debate may be a matter of much ado about nothing. Someone simply looking at W-L records is apt to have nearly as good of an idea of a team's true talent as someone calculating complicated formulas. Nevertheless, it comes as no surprise that using all three measurements gives a better result than using any one of the metrics.
While the Pythagorean method may be a more accurate measure of a team's true value, it hardly makes the a team's true WPCT obsolete. Simply knowing the components that go into winning a game cannot replace the knowledge of a team's actual record. Things such as bullpen usage, managerial strategy, and player motivation are not modeled in the Pythagorean method. The results of these models show that these factors cannot be ignored and thus, a team's actual W-L record is still relevant.
Comments
Good job, Sky. I haven't attempted a formal study of the issue but my intuition tells me that capping run differentials (at, say, five) on wins and losses on a game-by-game basis might yield the best results in terms of estimating a team's "true talent." This could make for a good study if you were up for it.
Posted by: Rich Lederer at August 11, 2009 9:28 AM
Would you care to share the projected winning percentages of all the teams for the rest of this year?
Posted by: Andrew at August 11, 2009 9:50 AM
Interesting study. Would you consider there to be any value in refining the predictions based on a "strength of schedule" factor?
At the 41 game mark you probably don't have a very balanced distribution of teams played. Perhaps you could compute expected winning percentages as you've done and then refine based on your estimates of opponents played strength?
Posted by: Jeff Gilham at August 11, 2009 10:40 AM
Good stuff, Sky. You might be interested in this "old" conversation:
http://www.battersbox.ca/article.php?story=20040923122101999&query=clay%2Bdavenport
Posted by: studes at August 11, 2009 12:58 PM
By the way, Rich, I once did a study capping the extra runs in games and found that it didn't help. In fact, it hurt a bit. Those extra runs do tell a bit more of the story.
Unfortunately, I have no idea where I posted that.
Posted by: studes at August 11, 2009 1:30 PM
Thanks for the comments. I think that overall adding strength of schedule would help - I think BP uses this to calculate their "3rd order wins".
Good idea to give the team expected WPCT's Andrew - I may do that if I have time. Though, as the article shows, you're bound to be nearly as accurate by just looking at regular WPCT.
Studes, I think I remember reading your piece somewhere. Unfortunately I don't remember where either!
Posted by: Sky Andrecheck at August 11, 2009 1:41 PM
"knowing the components that go into winning a game cannot replace the knowledge of a team's actual record. Things such as bullpen usage, managerial strategy, and player motivation are not modeled in the Pythagorean method."
Well yeah. What bothers me about the Pythagorean method is that it seems that being able to win close games is a skill, some teams do it better than others. It may be a question of having a better bullpen or better game strategy. A team that wins alot oc close games but gets blownout now and then will have a bad Pythagorean winning percentage but a good won loss record, and actually be a good team.
Pythagorean percentage might be more valuable used over three year periods, where being on the receiving end of occasional blowouts will have less impact on the statistics.
If we are trying to isolate the effect of luck on a season, and I think it actually has a pretty big effect, maybe the place to start is to see if a team had an unusually large or small number of injuries during the season? Sometimes you hear of cases where a bad season is explained due to a large number of injuries, but I have never heard a team's success explained by having no injuries that year, though this has happened.
Another place to look at is how well a team's opponents have been playing, the month in which they happen to be playing that team. Or whether an unusually large percentage of a team's wins came at the beginning of a season. Over the course of a season, a team can adjust and improve and a late season charge up the standings can result. A strong early season but mediocrity the rest of the way probably indicates luck.
Posted by: Ed at August 12, 2009 8:43 AM
This was a great analysis, but I wonder if it obscures the point of using Pythagorean methods to predict win/loss records. From my point of view, the main benefit of these methods is to try to identify teams that may have been particularly lucky or unlucky up to a certain point in a season, so we can get an idea of how we might expect them to perform the rest of the year. By taking a data set as large as the one used in this analysis, it seems that you are simply showing that the majority of teams are not particularly lucky or unlucky at all, even through only 40 games of a season. This is valuable data and an interesting conclusion, but I'm curious how well Pythag would perform through this large dataset if you look only at outliers.
The typical small-scale analysis done during the course of a season is to calculate the difference between Pythag-predicted Win% and actual record and identify outliers. The purpose is that using Pythagorean methods to predict the rest of the season should be better for these outliers than simply using their current Win%, but the assumption is that regular Win% should be just as good for the rest of the "luck-neutral" teams (which your analysis supports), and the number of outliers should be small. The question, then, would be whether or not Pythagorean methods actually do a better job of predicting rest-of-season record for these outliers than simply extrapolating current Win%.
Posted by: Will at August 12, 2009 10:42 AM
Sky,
I enjoyed your study, especially because I post a weekly feature involving component-based winning percentage estimates. Like a lot of things in sabermetrics, a lot of effort often results in very small improvements, especially when you look at average in a large dataset. Reminds me of the run estimator debates (though, like Will mentioned, it's at the extremes where things get interesting).
At BtB, Colin Wyers brought up the concern of multicollinearity with respect to the stability of the coefficients in your full model. How much does the R^2 (and adjusted R^2) change as you go from your simple models to your full model? When all variables are in your model, are any type-III tests of the coefficients significant? I'm guessing none are, because of the multicollinearity.
This would be consistent with your claim that there's minimal improvement in looking at components. But I'm not sure that you can claim strong support for the 1:1:2 weightings you propose at the end of the article, given how unreliable coefficients can become in multicollinear regression models...
Thoughts?
-j
Posted by: jinaz at August 12, 2009 7:10 PM
Nice posts from Ed, Will, and Jinaz - sorry for my tardiness in reply.
Jinaz, indeed there is collinearity between the estimates. Taking just one sample gives farily wild estimates for the coefficients because of it. However, things stabilize when taking over 100 such split-samples, so I'm fairly confident that those are the correct weights. The R-squared as you suggest, increases but does not change much.
Will, yes the points where there is a big difference between the Pythag and WPCT are the most interesting. However, this is also what drives the regression analysis. The cases with big differences are automatically given more weight.
Ed, indeed winning close games is a skill, which is why it still has weight in the model. If it was not a skill, but simply random, then using straight PythagWPCT would be best.
Posted by: Sky Andrecheck at August 18, 2009 10:00 AM