Rich Lederer • Baseball Beat
Patrick Sullivan • Change-Up
Jeremy Greenhouse • Touching Bases
Dave Allen • F/X Visualizations
Sky Andrecheck • Behind the Scoreboard
Marc Hulet • Around the Minors
Al Doyle • Past Times
Retired Uniforms:
Bryan Smith • WTNY
Joe Sheehan • Command Post
Jeff Albert • The Batter's Eye
RSS Feed
Home
*Examining the Past, Present, and Future*
Lineup Card
Recent Entries
» Putting Together a Reality Team
» Historical Hall of Fame Vote Comparisons: 2012
» An All-Christmas Team
» The New-Look Angels
» John Denny: The Forgotten Cy Young Award Winner
» Money Isn't Everything
» What Would It Take to Hit .400 in the 21st Century?
» Halos Heaven
» Brandon McCarthy's Breakout Season
» Link-o-Rama
» Historical Hall of Fame Vote Comparisons: 2012
» An All-Christmas Team
» The New-Look Angels
» John Denny: The Forgotten Cy Young Award Winner
» Money Isn't Everything
» What Would It Take to Hit .400 in the 21st Century?
» Halos Heaven
» Brandon McCarthy's Breakout Season
» Link-o-Rama
Best of Baseball Beat
Abstracts From the Abstracts
1977 Baseball Abstract
1978 Baseball Abstract
1979 Baseball Abstract
1980 Baseball Abstract
1981 Baseball Abstract
1982 Baseball Abstract
1983 Baseball Abstract
1984 Baseball Abstract
1985 Baseball Abstract
1986 Baseball Abstract
1987 Baseball Abstract
1988 Baseball Abstract
1978 Baseball Abstract
1979 Baseball Abstract
1980 Baseball Abstract
1981 Baseball Abstract
1982 Baseball Abstract
1983 Baseball Abstract
1984 Baseball Abstract
1985 Baseball Abstract
1986 Baseball Abstract
1987 Baseball Abstract
1988 Baseball Abstract
Bert Blyleven Series
Meeting Up and Hanging Out with Bert
The Results Are In And...
Aficionado Heavily Invested in Blyleven
Latest on Blyleven's Chances for the HOF
The Internet Zealot Responds
400 Down and 5 to Go...
Bert Be Home By Eleven?
Blyleven's Forgotten Season (1973)
HeyMan, Your Comments Don't Hold Water
The Waiting is the Hardest Part
Another Addition to the Blyleven Series
Search for the Truth
As Dominant as His HOF Contemporaries
Listen, Buster
A Larger Step for Blyleven
Answering the Naysayers (Part Two)
Another Small Step for Blyleven
Q&A: Blyleven on the Twins
The Majority Rules, Right?
It's All Dutch to Some
The Hall of Fame Case for Bert Blyleven
Q&A: Blyleven on Felix Hernandez
Clemens Rocketing Up Charts
Poz: An Interview With a KC Star
A HOF Chat with Tracy Ringolsby
Up Close and Personal
A Peek Into the Mind of a HOF Voter
Answering the Naysayers
It's That Time of the Year (Again)
"If Cooperstown is Calling..."
The Bert Alert
One Small Step for Blyleven...
Only the Lonely
The Results Are In And...
Aficionado Heavily Invested in Blyleven
Latest on Blyleven's Chances for the HOF
The Internet Zealot Responds
400 Down and 5 to Go...
Bert Be Home By Eleven?
Blyleven's Forgotten Season (1973)
HeyMan, Your Comments Don't Hold Water
The Waiting is the Hardest Part
Another Addition to the Blyleven Series
Search for the Truth
As Dominant as His HOF Contemporaries
Listen, Buster
A Larger Step for Blyleven
Answering the Naysayers (Part Two)
Another Small Step for Blyleven
Q&A: Blyleven on the Twins
The Majority Rules, Right?
It's All Dutch to Some
The Hall of Fame Case for Bert Blyleven
Q&A: Blyleven on Felix Hernandez
Clemens Rocketing Up Charts
Poz: An Interview With a KC Star
A HOF Chat with Tracy Ringolsby
Up Close and Personal
A Peek Into the Mind of a HOF Voter
Answering the Naysayers
It's That Time of the Year (Again)
"If Cooperstown is Calling..."
The Bert Alert
One Small Step for Blyleven...
Only the Lonely
Exclusive Interviews
Lee Sinins
Alex Belth
David Pinto
Will Carroll
Mike Carminati
Aaron Gleeman
Joe Sheehan
Jay Jaffe
Jeff Peek
Tracy Ringolsby
Joe Posnanski
Bill James Part I, II, III
Jon Lalonde
Chuck Tiffany
Dayn Perry
Fay Vincent
Nate Silver
Alex Belth
David Pinto
Will Carroll
Mike Carminati
Aaron Gleeman
Joe Sheehan
Jay Jaffe
Jeff Peek
Tracy Ringolsby
Joe Posnanski
Bill James Part I, II, III
Jon Lalonde
Chuck Tiffany
Dayn Perry
Fay Vincent
Nate Silver
Bullpen
Rich Lederer
The Odd Couple (with Alex Belth)
The MostUnder Over Underrated Player in Baseball (with Brian Gunn)
Three Wise Men (roundtable by Alex Belth)
Infrequently Asked Questions (interview with Matt Welch)
Interview (Orioles Think Tank)
Bernie and the Yanks (Bronx Banter)
Hope and Faith: How the LAA Win the World Series (Baseball Prospectus)
NL West (The Soul of Baseball)
Greatest Living Hitter? (Sports Illustrated)
Roundtable: 2008 HOF Ballot (Armchair GM)
The Most
Three Wise Men (roundtable by Alex Belth)
Infrequently Asked Questions (interview with Matt Welch)
Interview (Orioles Think Tank)
Bernie and the Yanks (Bronx Banter)
Hope and Faith: How the LAA Win the World Series (Baseball Prospectus)
NL West (The Soul of Baseball)
Greatest Living Hitter? (Sports Illustrated)
Roundtable: 2008 HOF Ballot (Armchair GM)
Patrick Sullivan
Designated Hitters
David Bromberg (Q&A: John Denny)
Mark Armour (H. Killebrew and Versatility)
Joe Lederer (Soundtrack of a Prospect)
David Bromberg (Clemente's Autograph)
David Bromberg (Woody Fryman)
D. Baumstein (WAR Against Age: Pitchers)
Doug Baumstein (The WAR Against Age)
Doug Baumstein (A Lifetime on the Road)
John Fraser (Pick Six)
Mark Armour (How to Score More Runs?)
Bill Parker (What Opening Day Tells Us)
Stan Opdyke (Pat Rispole)
Chris Jaffe (Evaluating Baseball's Mgrs)
Stan Opdyke (Baseball Radio in NYC, 1953)
A. Nathan (Performance of Baseball Bats)
Michael Weddell (Edgar Martinez/HOF)
Jon Weisman (100 Things Dodgers Fans...)
Stan Opdyke (Connie Mack and Vin Scully)
Eric Walker (Evaluating Run Production)
Brent Mayne (The Intangibles of Catching)
Chris Moore (Best Fastballs in Baseball)
Dave Baldwin (The Batter’s Brain)
Shawn Haviland (Ivy League to MLB)
Larry Granillo (Walking Off)
Rob Iracane (Solo HR Won't Break You)
Tommy Bennett (Charm of AM Radio)
Harry Pavlidis (Johan Santana's Fast Start)
John Walsh (WAR and Remembrance)
Eric Walker (Precisely Inaccurate)
Bob Timmermann (As They See 'Em)
Geoff Young (Unicycles and Delusions)
Baseball Analysis at Tufts (Groundballers)
Baseball Analysis at Tufts (GB Out Rates)
G. Rybarczyk ('09 Hit Tracker Projections)
Joe Lederer (Curt Schilling/HoF)
Conor Gallagher (Hall of Fallacies)
Chris Green (Jim Rice, HoF, the Numbers)
Shawn Hoffman (Baseball's Bear Mkt?)
Paul Anthony (Manny Syndrome)
Ross Roley (World Series Odds)
B. Timmermann (Catcher's Interference)
R.J. Anderson (Waiting the Hardest Part)
Maury Brown (Cubs, MLB, and Cuban...)
Myron Logan (Dee-Fense, Dee-Fense)
Craig Calcaterra (Frivolity, Part I, Part II)
Chad Finn (Ode to Baseball Cards)
David Cameron (Mariners Foibles)
Chris Dial (Chipper Jones)
Pat Lederer (Memory Lane)
David Appelman (Clutch Pitching)
Bob Rittner (DH)
Jonathan Mayo (Roger Clemens)
Lisa Winston (My Son-in-Law...)
Russ McQueen (The Yellow Hammer)
Bob Rittner (I'm OK, You're OK)
Mark Armour (In Defense of the HOF)
Pat Jordan (Friends)
Dan Levitt (Analysis of Terry Ryan)
Doug Baumstein (Trading Econ 101)
Ross Roley (Runner's Reluctance II)
Ross Roley (Runner's Reluctance I)
Mark Armour (No-Longer Lovable Sox)
Bruce Regal (Stealthy and Wise)
Brian Gunn (Roid Monster)
Current/McEvoy (Value of the SB)
John Rickert (Sinister Thefts)
Nate Silver (Sabermetrics)
David Vincent (Home Run Production)
Joe P. Sheehan (Enhanced Gameday II)
Mark Armour (An Ode to Sport)
David Gassko (All-Time Worm Burners)
Joe P. Sheehan (Enhanced Gameday)
John Walsh (When Titans Clash)
Fox/Williams (Quantifying Coaches II)
Fox/Williams (Quantifying Coaches I)
Jacob Luft (Bull Durham Rant)
Chad Finn (Strat-O-Matic)
Lisa Winston (Rotisserie Baseball)
Dave Studeman (Baseball Stats)
Steve Treder (Roger Craig)
Marc Normandin (Jeff Bagwell)
D. Appelman (Expanding Strike Zone)
Jeff Sackmann (Worst MiL Defenders)
Jeff Sackmann (Best MiL Defenders)
Maxwell Kates (Van Lingle Mungo)
David Appelman (Pitch Location)
Kent Bonham (Danny Ray Herrera)
Glenn Stout (Two Baseball Poems)
Bruce Regal (The Challenge Round)
Mark Lamster (Barry & Ty)
Geoff Young (NL West)
Tom Lederer (The Ryan Express)
Brian Erts (Great Leap Forward)
David Pinto (Parity and the N.L.)
Jacob Luft (Fathers and Daughters)
Jamey Newberg (Pete's Sake)
Jeff Albert (A. Jones Swing Analysis)
Jeff Albert (A-Rod Swing Analysis)
Keith Law (Death, Taxes, and Waivers)
Peter Abraham (Tales of Torre Tales)
Larry Borowsky (Let 'er Rip II)
Dan Levitt (Empirical Analysis of Bunting)
Jonah Keri (If I Met Warren Cromartie...)
Bob Klapisch (War Stories)
Bob Timmermann (John F. Kennedy HS)
Kent Bonham (Aluminum Adjustments)
Al Doyle (More Than Superstars)
Ross Roley (Instant Replay)
David Vincent (Barry Bonds Homers)
Chad Finn (Our Favorite Obscurities)
Bill Deane (1979 NL MVP)
Mark Armour (Rise/Fall of Artificial Turf)
Jeff Angus (Wally Moon Camp)
David Berri (Money and Baseball)
Larry Borowsky (Baseball w/o the #s)
Derek Zumsteg (The Irrational Market)
David Regan (Free Agent Contracts)
Peter Schmuck (Steroids and the HOF)
David Appelman (Pitchers, Pitch by Pitch)
Dan Fox (Swinging, Taking, Fouling, Etc)
Patrick Sullivan (Study of NYY CF/BOS LF)
Will Leitch (Baseball Journalism)
Jeff Sullivan (Pitcher Release Points)
Steve Treder ('69-'70 Giants)
Maury Brown (Charlie Finley)
John Brattain (Bob Johnson)
Bob Klapisch (The Case for Bert Blyleven)
Jeff Peek (Pride and Prejudice)
Dayn Perry (Bert and Warren)
Rob Neyer (If Don Sutton Was Great...)
Lisa Winston (Minor League Memories)
Alex Belth (Otis Redding Was Right)
David Cameron (Long Live the King)
Jeff Angus (Baserunning Study)
Bert Blyleven (Baseball Playoffs)
Boyd Nation (Not a Prospect List)
James Click (Batters-Baserunners Study)
Jeff Shaw (Why I Love Baseball)
David Gassko (BIP/BFP Fielding Study)
Jay Jaffe (Milwaukee Sausage Race)
Jamey Newberg (Remember When)
Bob Klapisch (Press Box to the Mound)
Dan Levitt (Predictive Value of BB)
David Vincent (Official Scorer)
Jon Weisman (Rick Monday)
Larry Borowsky (Let 'er Rip)
Will Carroll (Fictional Short Story)
Bob Timmermann (Japanese Baseball)
Cyril Morong (Best Pitching Seasons)
Sean Forman (Monte Carlo Win-Loss)
Brian Gunn (My Little Blue Book)
Joe Lederer (My Dad and Baseball)
Bill Deane (Bob Gibson, 1968)
Mark Armour (1977 Yankees)
Darren Viola (Retrosheet)
David Pinto (RFK)
Dayn Perry (Brave Heart)
Matt Welch (Dave Hansen)
Kevin Kernan (Jack McKeon)
Tom Lederer (Dodgers Road Trip)
Steve Lombardi (Slider)
Studes (Picturing Baseball)
Mike Carminati (Luck of the Drawl)
Eric Neel (Vin Scully)
J.C. Bradbury (Leo Mazzone)
John Sickels (Bill James)
Mark Armour (H. Killebrew and Versatility)
Joe Lederer (Soundtrack of a Prospect)
David Bromberg (Clemente's Autograph)
David Bromberg (Woody Fryman)
D. Baumstein (WAR Against Age: Pitchers)
Doug Baumstein (The WAR Against Age)
Doug Baumstein (A Lifetime on the Road)
John Fraser (Pick Six)
Mark Armour (How to Score More Runs?)
Bill Parker (What Opening Day Tells Us)
Stan Opdyke (Pat Rispole)
Chris Jaffe (Evaluating Baseball's Mgrs)
Stan Opdyke (Baseball Radio in NYC, 1953)
A. Nathan (Performance of Baseball Bats)
Michael Weddell (Edgar Martinez/HOF)
Jon Weisman (100 Things Dodgers Fans...)
Stan Opdyke (Connie Mack and Vin Scully)
Eric Walker (Evaluating Run Production)
Brent Mayne (The Intangibles of Catching)
Chris Moore (Best Fastballs in Baseball)
Dave Baldwin (The Batter’s Brain)
Shawn Haviland (Ivy League to MLB)
Larry Granillo (Walking Off)
Rob Iracane (Solo HR Won't Break You)
Tommy Bennett (Charm of AM Radio)
Harry Pavlidis (Johan Santana's Fast Start)
John Walsh (WAR and Remembrance)
Eric Walker (Precisely Inaccurate)
Bob Timmermann (As They See 'Em)
Geoff Young (Unicycles and Delusions)
Baseball Analysis at Tufts (Groundballers)
Baseball Analysis at Tufts (GB Out Rates)
G. Rybarczyk ('09 Hit Tracker Projections)
Joe Lederer (Curt Schilling/HoF)
Conor Gallagher (Hall of Fallacies)
Chris Green (Jim Rice, HoF, the Numbers)
Shawn Hoffman (Baseball's Bear Mkt?)
Paul Anthony (Manny Syndrome)
Ross Roley (World Series Odds)
B. Timmermann (Catcher's Interference)
R.J. Anderson (Waiting the Hardest Part)
Maury Brown (Cubs, MLB, and Cuban...)
Myron Logan (Dee-Fense, Dee-Fense)
Craig Calcaterra (Frivolity, Part I, Part II)
Chad Finn (Ode to Baseball Cards)
David Cameron (Mariners Foibles)
Chris Dial (Chipper Jones)
Pat Lederer (Memory Lane)
David Appelman (Clutch Pitching)
Bob Rittner (DH)
Jonathan Mayo (Roger Clemens)
Lisa Winston (My Son-in-Law...)
Russ McQueen (The Yellow Hammer)
Bob Rittner (I'm OK, You're OK)
Mark Armour (In Defense of the HOF)
Pat Jordan (Friends)
Dan Levitt (Analysis of Terry Ryan)
Doug Baumstein (Trading Econ 101)
Ross Roley (Runner's Reluctance II)
Ross Roley (Runner's Reluctance I)
Mark Armour (No-Longer Lovable Sox)
Bruce Regal (Stealthy and Wise)
Brian Gunn (Roid Monster)
Current/McEvoy (Value of the SB)
John Rickert (Sinister Thefts)
Nate Silver (Sabermetrics)
David Vincent (Home Run Production)
Joe P. Sheehan (Enhanced Gameday II)
Mark Armour (An Ode to Sport)
David Gassko (All-Time Worm Burners)
Joe P. Sheehan (Enhanced Gameday)
John Walsh (When Titans Clash)
Fox/Williams (Quantifying Coaches II)
Fox/Williams (Quantifying Coaches I)
Jacob Luft (Bull Durham Rant)
Chad Finn (Strat-O-Matic)
Lisa Winston (Rotisserie Baseball)
Dave Studeman (Baseball Stats)
Steve Treder (Roger Craig)
Marc Normandin (Jeff Bagwell)
D. Appelman (Expanding Strike Zone)
Jeff Sackmann (Worst MiL Defenders)
Jeff Sackmann (Best MiL Defenders)
Maxwell Kates (Van Lingle Mungo)
David Appelman (Pitch Location)
Kent Bonham (Danny Ray Herrera)
Glenn Stout (Two Baseball Poems)
Bruce Regal (The Challenge Round)
Mark Lamster (Barry & Ty)
Geoff Young (NL West)
Tom Lederer (The Ryan Express)
Brian Erts (Great Leap Forward)
David Pinto (Parity and the N.L.)
Jacob Luft (Fathers and Daughters)
Jamey Newberg (Pete's Sake)
Jeff Albert (A. Jones Swing Analysis)
Jeff Albert (A-Rod Swing Analysis)
Keith Law (Death, Taxes, and Waivers)
Peter Abraham (Tales of Torre Tales)
Larry Borowsky (Let 'er Rip II)
Dan Levitt (Empirical Analysis of Bunting)
Jonah Keri (If I Met Warren Cromartie...)
Bob Klapisch (War Stories)
Bob Timmermann (John F. Kennedy HS)
Kent Bonham (Aluminum Adjustments)
Al Doyle (More Than Superstars)
Ross Roley (Instant Replay)
David Vincent (Barry Bonds Homers)
Chad Finn (Our Favorite Obscurities)
Bill Deane (1979 NL MVP)
Mark Armour (Rise/Fall of Artificial Turf)
Jeff Angus (Wally Moon Camp)
David Berri (Money and Baseball)
Larry Borowsky (Baseball w/o the #s)
Derek Zumsteg (The Irrational Market)
David Regan (Free Agent Contracts)
Peter Schmuck (Steroids and the HOF)
David Appelman (Pitchers, Pitch by Pitch)
Dan Fox (Swinging, Taking, Fouling, Etc)
Patrick Sullivan (Study of NYY CF/BOS LF)
Will Leitch (Baseball Journalism)
Jeff Sullivan (Pitcher Release Points)
Steve Treder ('69-'70 Giants)
Maury Brown (Charlie Finley)
John Brattain (Bob Johnson)
Bob Klapisch (The Case for Bert Blyleven)
Jeff Peek (Pride and Prejudice)
Dayn Perry (Bert and Warren)
Rob Neyer (If Don Sutton Was Great...)
Lisa Winston (Minor League Memories)
Alex Belth (Otis Redding Was Right)
David Cameron (Long Live the King)
Jeff Angus (Baserunning Study)
Bert Blyleven (Baseball Playoffs)
Boyd Nation (Not a Prospect List)
James Click (Batters-Baserunners Study)
Jeff Shaw (Why I Love Baseball)
David Gassko (BIP/BFP Fielding Study)
Jay Jaffe (Milwaukee Sausage Race)
Jamey Newberg (Remember When)
Bob Klapisch (Press Box to the Mound)
Dan Levitt (Predictive Value of BB)
David Vincent (Official Scorer)
Jon Weisman (Rick Monday)
Larry Borowsky (Let 'er Rip)
Will Carroll (Fictional Short Story)
Bob Timmermann (Japanese Baseball)
Cyril Morong (Best Pitching Seasons)
Sean Forman (Monte Carlo Win-Loss)
Brian Gunn (My Little Blue Book)
Joe Lederer (My Dad and Baseball)
Bill Deane (Bob Gibson, 1968)
Mark Armour (1977 Yankees)
Darren Viola (Retrosheet)
David Pinto (RFK)
Dayn Perry (Brave Heart)
Matt Welch (Dave Hansen)
Kevin Kernan (Jack McKeon)
Tom Lederer (Dodgers Road Trip)
Steve Lombardi (Slider)
Studes (Picturing Baseball)
Mike Carminati (Luck of the Drawl)
Eric Neel (Vin Scully)
J.C. Bradbury (Leo Mazzone)
John Sickels (Bill James)
Search Baseball Analysts
Archives
By Category:
Around the Majors Content Only
Around the Minors Content Only
Baseball Beat Content Only
Baseball Beat/Change-Up Content Only
Baseball Beat/WTNY Content Only
Behind the Scoreboard Content Only
Change-Up Content Only
Change-Up/Around the Majors Content Only
Command Post Content Only
Crunching the Numbers Content Only
Designated Hitter Content Only
F/X Visualizations Content Only
Past Times Content Only
Saber Talk Content Only
The Batter's Eye Content Only
Touching Bases Content Only
Weekend Blog Content Only
WTNY Content Only
Around the Minors Content Only
Baseball Beat Content Only
Baseball Beat/Change-Up Content Only
Baseball Beat/WTNY Content Only
Behind the Scoreboard Content Only
Change-Up Content Only
Change-Up/Around the Majors Content Only
Command Post Content Only
Crunching the Numbers Content Only
Designated Hitter Content Only
F/X Visualizations Content Only
Past Times Content Only
Saber Talk Content Only
The Batter's Eye Content Only
Touching Bases Content Only
Weekend Blog Content Only
WTNY Content Only
By Month:
February 2012
January 2012
December 2011
October 2011
September 2011
August 2011
July 2011
June 2011
May 2011
April 2011
March 2011
February 2011
January 2011
December 2010
November 2010
October 2010
September 2010
August 2010
July 2010
June 2010
May 2010
April 2010
March 2010
February 2010
January 2010
December 2009
November 2009
October 2009
September 2009
August 2009
July 2009
June 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
October 2008
September 2008
August 2008
July 2008
June 2008
May 2008
April 2008
March 2008
February 2008
January 2008
December 2007
November 2007
October 2007
September 2007
August 2007
July 2007
June 2007
May 2007
April 2007
March 2007
February 2007
January 2007
December 2006
November 2006
October 2006
September 2006
August 2006
July 2006
June 2006
May 2006
April 2006
March 2006
February 2006
January 2006
December 2005
November 2005
October 2005
September 2005
August 2005
July 2005
June 2005
May 2005
April 2005
March 2005
February 2005
January 2005
December 2004
November 2004
October 2004
September 2004
August 2004
July 2004
June 2004
May 2004
April 2004
March 2004
February 2004
January 2004
December 2003
November 2003
October 2003
September 2003
August 2003
July 2003
June 2003
January 2012
December 2011
October 2011
September 2011
August 2011
July 2011
June 2011
May 2011
April 2011
March 2011
February 2011
January 2011
December 2010
November 2010
October 2010
September 2010
August 2010
July 2010
June 2010
May 2010
April 2010
March 2010
February 2010
January 2010
December 2009
November 2009
October 2009
September 2009
August 2009
July 2009
June 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
October 2008
September 2008
August 2008
July 2008
June 2008
May 2008
April 2008
March 2008
February 2008
January 2008
December 2007
November 2007
October 2007
September 2007
August 2007
July 2007
June 2007
May 2007
April 2007
March 2007
February 2007
January 2007
December 2006
November 2006
October 2006
September 2006
August 2006
July 2006
June 2006
May 2006
April 2006
March 2006
February 2006
January 2006
December 2005
November 2005
October 2005
September 2005
August 2005
July 2005
June 2005
May 2005
April 2005
March 2005
February 2005
January 2005
December 2004
November 2004
October 2004
September 2004
August 2004
July 2004
June 2004
May 2004
April 2004
March 2004
February 2004
January 2004
December 2003
November 2003
October 2003
September 2003
August 2003
July 2003
June 2003
Reference
Organizational Stats
Arizona Diamondbacks Bat / Pitch
Atlanta Braves Bat / Pitch
Baltimore Orioles Bat / Pitch
Boston Red Sox Bat / Pitch
Chicago Cubs Bat / Pitch
Chicago White Sox Bat / Pitch
Cincinnati Reds Bat / Pitch
Cleveland Indians Bat / Pitch
Colorado Rockies Bat / Pitch
Detroit Tigers Bat / Pitch
Florida Marlins Bat / Pitch
Houston Astros Bat / Pitch
Kansas City Royals Bat / Pitch
Los Angeles Angels Bat / Pitch
Los Angeles Dodgers Bat / Pitch
Milwaukee Brewers Bat / Pitch
Minnesota Twins Bat / Pitch
New York Mets Bat / Pitch
New York Yankees Bat / Pitch
Oakland Athletics Bat / Pitch
Philadelphia Phillies Bat / Pitch
Pittsburgh Pirates Bat / Pitch
St. Louis Cardinals Bat / Pitch
San Diego Padres Bat / Pitch
San Francisco Giants Bat / Pitch
Seattle Mariners Bat / Pitch
Tampa Bay Devil Rays Bat / Pitch
Texas Rangers Bat / Pitch
Toronto Blue Jays Bat / Pitch
Washington Nationals Bat / Pitch
Atlanta Braves Bat / Pitch
Baltimore Orioles Bat / Pitch
Boston Red Sox Bat / Pitch
Chicago Cubs Bat / Pitch
Chicago White Sox Bat / Pitch
Cincinnati Reds Bat / Pitch
Cleveland Indians Bat / Pitch
Colorado Rockies Bat / Pitch
Detroit Tigers Bat / Pitch
Florida Marlins Bat / Pitch
Houston Astros Bat / Pitch
Kansas City Royals Bat / Pitch
Los Angeles Angels Bat / Pitch
Los Angeles Dodgers Bat / Pitch
Milwaukee Brewers Bat / Pitch
Minnesota Twins Bat / Pitch
New York Mets Bat / Pitch
New York Yankees Bat / Pitch
Oakland Athletics Bat / Pitch
Philadelphia Phillies Bat / Pitch
Pittsburgh Pirates Bat / Pitch
St. Louis Cardinals Bat / Pitch
San Diego Padres Bat / Pitch
San Francisco Giants Bat / Pitch
Seattle Mariners Bat / Pitch
Tampa Bay Devil Rays Bat / Pitch
Texas Rangers Bat / Pitch
Toronto Blue Jays Bat / Pitch
Washington Nationals Bat / Pitch
All-Star Links
Official Websites
News and Notes
Baseball News Blog
Baseball Newstand
ESPN Baseball
Fox Sports Baseball
Pro Sports Daily
Roto World
The Roto Times
USA Today Baseball
Baseball Newstand
ESPN Baseball
Fox Sports Baseball
Pro Sports Daily
Roto World
The Roto Times
USA Today Baseball
Reference and Analysis
Baseball Almanac
Baseball America
Baseball Archive
Baseball Contracts
Baseball Cube
Baseball Graphs
Baseball Library
Baseball Musings Player Database
Baseball Page
Baseball Primer
Baseball Prospectus
Baseball Reference
Baseball Statistics
Baseball Truth
Boxscore Central
Diamond Mind Baseball
Doug's Stats
FanGraphs
Fast Balls (pitchfx catalog)
Hardball Dollars
Hardball Times
Hit Tracker
Retrosheet
Rotobase/Rotoblog
Stat Corner
STATS
Tango on Baseball
Yahoo Sports MLB
Baseball America
Baseball Archive
Baseball Contracts
Baseball Cube
Baseball Graphs
Baseball Library
Baseball Musings Player Database
Baseball Page
Baseball Primer
Baseball Prospectus
Baseball Reference
Baseball Statistics
Baseball Truth
Boxscore Central
Diamond Mind Baseball
Doug's Stats
FanGraphs
Fast Balls (pitchfx catalog)
Hardball Dollars
Hardball Times
Hit Tracker
Retrosheet
Rotobase/Rotoblog
Stat Corner
STATS
Tango on Baseball
Yahoo Sports MLB
Web Gems
Bill James Primer
Sabermetric Manifesto (Grabiner)
Pitching and Defense (McCracken)
Pitching and Defense (Tippett)
Transactions Primer (Neyer)
Baseball Stats (Batter's Box)
Prospect Report (Cameron)
Pitcher Workloads (Sheehan)
Goodbye to Old Baseball Ideas (Rickey)
Sabermetric Manifesto (Grabiner)
Pitching and Defense (McCracken)
Pitching and Defense (Tippett)
Transactions Primer (Neyer)
Baseball Stats (Batter's Box)
Prospect Report (Cameron)
Pitcher Workloads (Sheehan)
Goodbye to Old Baseball Ideas (Rickey)
Columnists
Baseball Blogs
Around the Majors
Athletics Nation
Baseball Crank
Baseball Musings
Baseball-Reference Blog
Batter's Box
Big League Stew
Bronx Banter
Catfish Stew
Cub Town
Dan Agonistes
Dodger Thoughts
DRays Bay
Ducksnorts
Futility Infielder
Halos Heaven
Inside the Rockies
It Might Be Dangerous
Knuckle Curve
LoHud Yankees Blog
Lookout Landing
Management by Baseball
Metaforian
Metsgeek
Mike's Baseball Rants
Only Baseball Matters
Redbird Nation
Red Reporter
Sabernomics (Braves)
Seth Speaks
ShysterBall
6-4-2 (Angels/Dodgers)
The Book
TheCubdom
The Cutting Edge
The House That Dewey Built
The View From The Bleachers
Tiger Blog
U.S.S. Mariner
Viva El Birdos
Where's Kernan
Athletics Nation
Baseball Crank
Baseball Musings
Baseball-Reference Blog
Batter's Box
Big League Stew
Bronx Banter
Catfish Stew
Cub Town
Dan Agonistes
Dodger Thoughts
DRays Bay
Ducksnorts
Futility Infielder
Halos Heaven
Inside the Rockies
It Might Be Dangerous
Knuckle Curve
LoHud Yankees Blog
Lookout Landing
Management by Baseball
Metaforian
Metsgeek
Mike's Baseball Rants
Only Baseball Matters
Redbird Nation
Red Reporter
Sabernomics (Braves)
Seth Speaks
ShysterBall
6-4-2 (Angels/Dodgers)
The Book
TheCubdom
The Cutting Edge
The House That Dewey Built
The View From The Bleachers
Tiger Blog
U.S.S. Mariner
Viva El Birdos
Where's Kernan
Minor Leagues
Arizona Fall League
BA Player Finder
Cal Leaguers
Jamey Newberg
JDM's Scoresheet Baseball
Minor League Baseball
Minor League Park Factors
Minor League Splits
No Pepper
Sickels' Minor League Ball
Warm October Nights
BA Player Finder
Cal Leaguers
Jamey Newberg
JDM's Scoresheet Baseball
Minor League Baseball
Minor League Park Factors
Minor League Splits
No Pepper
Sickels' Minor League Ball
Warm October Nights
Amateur
Boyd's World (College)
Cape Cod Baseball League
College Baseball Blog
College Baseball Insider
Collegiate Baseball Newspaper
College Splits
College Splits Blog
Dirtbags Baseball (Long Beach State)
NCAA Baseball
NCBWA
Team One Baseball (High School)
Texas A&M & Baseball
Cape Cod Baseball League
College Baseball Blog
College Baseball Insider
Collegiate Baseball Newspaper
College Splits
College Splits Blog
Dirtbags Baseball (Long Beach State)
NCAA Baseball
NCBWA
Team One Baseball (High School)
Texas A&M & Baseball
Historical
Cuban Baseball
House of David
Jim "Mudcat" Grant's Web Page
Negro League Baseball Players Assoc
Negro Leagues Baseball Museum
1919 Black Sox
Pacific Coast League
Philadelphia Athletics Historical Society
Shoeless Joe Jackson Society
SABR-L Archives
Walter O'Malley
House of David
Jim "Mudcat" Grant's Web Page
Negro League Baseball Players Assoc
Negro Leagues Baseball Museum
1919 Black Sox
Pacific Coast League
Philadelphia Athletics Historical Society
Shoeless Joe Jackson Society
SABR-L Archives
Walter O'Malley
Miscellaneous
Forums
Credits
Ticket Center
Tickets to Baseball -
Premium Red Sox Tickets - Tickets to Marlins Games - Cardinals Game Tickets - NY Yankee Tickets - Tickets Oakland Athletics - Dallas Cowboys Tickets - Arizona Cardinals Tickets - Tickets Seattle Seahawks - Buffalo Bills Tickets Online - Tickets to Dolphins Football
Buy Boston Red Sox tickets,
Philadelphia Phillies tix,
NY Yankees tickets,
NY Mets tickets, and
MLB All Star game tickets at ABC tickets
Not sure where to find the best online sportsbooks? Start your search with PlayersJet.
Get deals at SportsMemorabilia.com on baseball apparel, including Phillies jerseys and more for adults and children.
Shop the largest selection baseball equipment on sale at Sports Unlimited. Check out tons of baseball gloves, youth baseball gloves and catchers gear from Rawlings, Wilson, Nike & Under Armour.
2011 Draft Order
Courtesy of Baseball America
First-Round:
1. Pirates (57-105) 2. Mariners (61-101) 3. Diamondbacks (65-97) 4. Orioles (66-96) 5. Royals (67-95) 6. Nationals (69-93) 7. Diamondbacks (for B. Loux) 8. Indians (69-93) 9. Cubs (75-87) 10. Padres (for Karsten Whitson) 11. Astros (76-86) 12. Brewers (77-85) 13. Mets (79-83) 14. Marlins (80-82) 15. Brewers (for Dylan Covey) 16. Dodgers (80-82) 17. Angels (80-82) 18. Athletics (81-81) 19. Red Sox (from DET for Martinez) 20. Rockies (83-79) 21. Blue Jays (85-77) 22. Cardinals (86-76) 23. Nationals (from CWS for Dunn) 24. Rays (from BOS for Crawford) 25. Padres (90-72) 26. Red Sox (from TEX for Beltre) 27. Reds (91-71) 28. Braves (91-71) 29. Giants (92-70) 30. Twins (94-68) 31. Rays (from NYY for Soriano) 32. Rays (96-66) 33. Rangers (from PHI for Lee)Supplemental First Round:
34. Nationals (Dunn) 35. Blue Jays (Downs) 36. Red Sox (Martinez) 37. Rangers (Lee) 38. Rays (Crawford) 39. Phillies (Werth) 40. Red Sox (Beltre) 41. Rays (Soriano) 42. Rays (Balfour) 43. Diamondbacks (LaRoche) 44. Mets (Feliciano) 45. Rockies (Dotel) 46. Blue Jays (Buck) 47. White Sox (Putz) 48. Padres (Garland) 49. Giants (Uribe) 50. Twins (Hudson) 51. Yankees (Vazquez) 52. Rays (Benoit) 53. Blue Jays (Olivo) 54. Padres (Torrealba) 55. Twins (Crain) 56. Rays (Choate) 57. Blue Jays (Gregg) 58. Padres (Correia) 59. Rays (Hawpe)
| Designated Hitter | April 16, 2009 |
Precisely Inaccurate
Perhaps the widest and deepest pitfall lying in wait for any who deal in numerical analyses is forgetting the distinction between precision and accuracy. If I state that Team X's opening-day first pitch was delivered at 1:07:32 pm, I am being quite precise; but if in fact it was a night game, then the statement that the pitch was made sometime between 7:35 and 7:40 pm, though far less precise, is far more accurate.
It is all too easy to be hypnotized by the ability to calculate some metric to a large number of decimal places into believing that such precision equates to accuracy. As a case in point, let us look over the concept of "park factors". It is undoubtable that ballparks influence the results that players achieve playing in them, and in many cases--"many" both as to particular parks and as to particular statistics--those influences are substantial. Park factors are intended as correctives, numbers that ideally allow inflating or deflating actual player or team results in a way that neutralizes park effects and give us a more nearly unbiased look at those players' and teams' abilities and achievements. So much virtually everyone knows.
The idea behind the construction of park factors, stated broadly, is to compare performance in a given park with performance elsewhere. As an example, a widely used method for educing park factors for a simple but basic metric, run scoring, is the one used by (but not original to) ESPN. The elements that go into it are team runs scored (R) and opponents' runs scored (OR) at home and away, and total games played at home and away.
(Rh + ORh) ÷ Gh
factor = ───────────────
(Ra + ORa) ÷ Ga
That comes down to average combined (team plus opponents) runs scored per game at home divided by the corresponding figure for away games. Let us see what some of the things wrong with that basic approach are, and if we can improve on it.
A "park factor" is supposed to tell us how the park affects some datum--here, run scoring. Perhaps the most obvious failing of the ESPN method is made manifest by the simple question compared to what? In the calculation above, run scoring at Park X is being compared to run scoring at all parks except X. Thus, each park for which we calculate such a factor is being compared to some different basis: the pool of "away" parks for Park X is obviously different from the pool of "away" parks for Park Y (in that X's pool includes Y but excludes X itself, while Y's includes X but excludes Y itself). Now that rather basic folly can be fairly easily corrected for; let's call the average combined runs per game at home and away RPGh and RPGa, respectively. Then, if there are T teams in the league,
RPGh
factor = ───────────────────────────────
{[RPGa x (T - 1)] [RPGh]} ÷ T
But there remain considerable problems, the most obvious being that the pools are still not identical, in that schedules are not perfectly balanced: Teams X and Y can, and probably do, play significantly different numbers of games in each of the other parks. Even if we throw out inter-league data, which is especially corrupt owing to the variable use of the DH Rule, we still have differing pools for differing teams, at least by division (and possibly even within divisions, owing to rainouts never made up). Well, one thinks, we can see how to deal with that: we would normalize away data park by park, then combine the results, so the "away" pool would, finally, represent the imaginary "league-average park" against which we would ideally like to compare any particular park's effects.
Let us remain aware, however, before we move on, that there are yet other difficulties. We have been using the simple--or rather, simplistic--idea of "games" as the basis for comparing parks' effects on run scoring. But even at that level, there are inequalities needing adjustment, in that the numbers of innings are not going to be equally apportioned among home batters, away batters, home pitchers, and away pitchers, in that a winning team at home does not bat in the bottom of the last inning. There is also the further question of whether innings are the proper basis for comparison. For most stats, the wanted basis for comparison is batter-pitcher confrontations, whether styled PA or BFP. But there are complexities there, too. A batter's ability to get walked, or a pitcher's tendency to give up walks, might seem best based on PAs or BFPs; but higher numbers of walks mean a higher on-base percentage, which means that more batters will get a chance to come to the plate (it is that "compound-interest effect" of OBA that is often not properly factored into metrics of run-generation, individual or team: not only is the chance of a batter becoming a run raised, but the chance of getting that chance is also raised). That will increase run scoring in a manner that a metric measured against PAs will not fully capture. And there are yet other questions, such as whether strikeouts should be normalized to plate appearances or to at-bats.
But for our purposes here--getting a grand overview of the plausibility of "park factors"--such niceties, while of interest, can be set aside. Let's look at the larger picture. Let's say we want to get a Runs park factor for Park X. We have seen that we need to use normalized runs per game on a park-by-park basis if we are to avoid gross distortions from schedule imbalances and related factors. How might that look for a real-world example? Let's take, arbitrarily, San Francisco in 2008. Here are the raw data:

And here are the consequent paired raw factors:

But, because we have used a particular park for these figurings, all those numbers are relative to that park. What we want are numbers relative to that imaginary "league-average" park. For example, if we had chosen the stingiest park in the league, all the factors would be greater than 1; had we chosen the most generous, all the factors would be under 1. But all we have to do is average the various factors--in which process we assign the park itself, here San Francisco (I refuse to use the corporate-name-of-the-day for that or any park), a value of 1, since it is necessarily identical to itself--and then normalize the factors relative to that average. When we do that, we get what ought to be the runs "park factor" for each National-League park relative to an imaginary all-NL average park:

The average is not exactly 1.000 owing to rounding errors, but it's close enough for government work. If we sort that assemblage, it looks like this:
But before we jump to any conclusions whatever about those results, let's ponder this: they were derived from data for one park, one team. Yet, if the methodology is sound, we ought to get at least roughly the same results no matter which park we initially use. Imagine a Twilight-Zone universe in which the 2008 season was played out in some timeless place where each team played ten thousand games with each other team, yet still at their natural and normal performance levels as they were in 2008. Surely it is clear that we then could indeed use any one park as a basis for deriving "park factors" since, in the end, we normalize away that park to reach an all-league basis. In that Twilight Zone world, any variations from using this or that particular park can only be relatively minor random statistical noise. San Francisco is to Los Angeles thus, and San Francisco is to San Diego so, hence Los Angeles is to San Diego thus-and-so (in a manner of speaking). So what do we see if we try real calculations with real one-season data? Let's continue with the National League in 2008. Shown are the "park runs factors" for each park as calculated from each of the other parks as a basis. If the concept is sound, the numbers in each row across ought to be roughly the same. Ha.
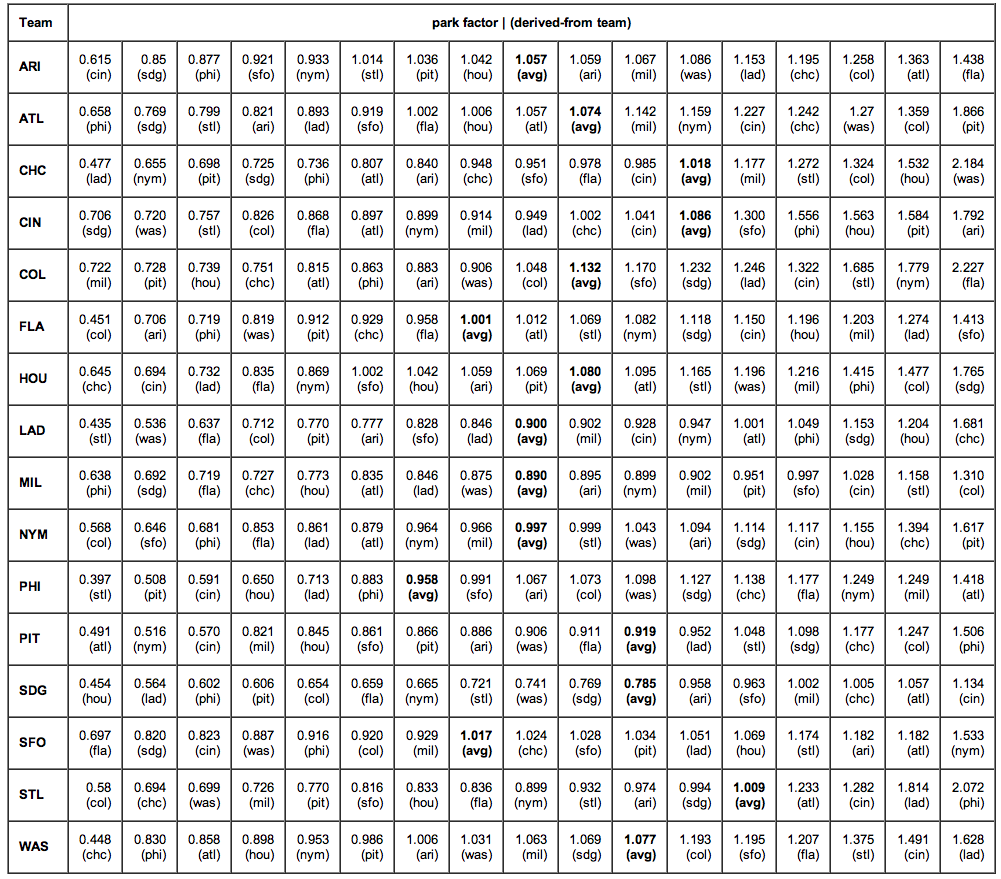
Well, now we know something, don't we? This just doesn't work. But it's not the methodology. Nor is it the various minor factors we saw earlier: those don't produce 3:1 and greater spreads in estimation. No, what we are dealing here, plain and simple, is the traditional statistical bugaboo--an inadequate sample size. Here is a possibly instructive presentation: the averaged run-factor values from that table above compared to what the simplistic ESPN formula yields:
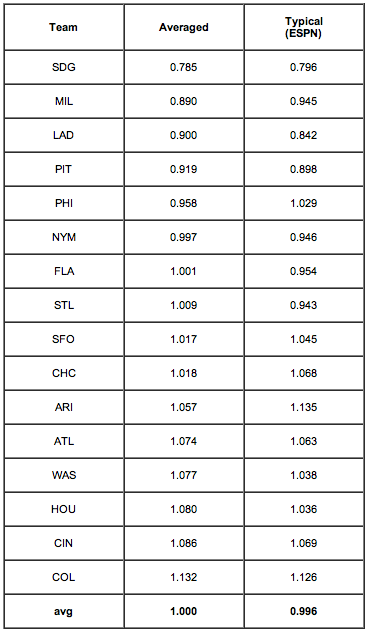
Instructive, indeed. The agreement is not perfect, as we would not expect it to be. The "average" column is a little better than the ESPN column because it allows better for the differing numbers of games on the schedule, but by using the average for each park of the values derived from all the other parks we are approximating the ESPN method.
The entire point of this lengthy demonstration has been to lift the lid off those nice, clean-looking, precise park-effect numbers to show the seething boil in the pot. The end results are not totally meaningless: we can say with fair credibility that San Diego's is a considerably more pitcher-friendly park than Colorado's, and that the Mets and the Marlins were playing in parks without gross distorting effects. But to try to numerically correct any team's results--much less any particular player's results--by means of "park factors" is very, very wrong.
But wait, there's more! (As they say on TV.) If the problem is a shortage of data, why not simply expand the sample size? Use multi-year data? That would be nice, and useful, were no park changed structurally over a period of some years. But consider: not even counting structural changes, in the last ten seasons (counting 2009), a full dozen totally new ballparks have come on line. When one considers that pace, plus the changes (some even to a few of those new parks), it becomes painfully obvious that trying multi-year data is as bad or worse. Even for a particular park that might itself not have been at all changed for many years, there remains the issue that the standard of comparison--that imaginary league-average park--will have changed, probably quite a lot, over that time, owing to changes in the other real parks. So we can't use multi-season values, and single-season values are comically insufficient for anything beyond broad-brush estimations, estimations more qualitative than quantitative.
I should point out that none of this is today's news. In 2007, Greg Rybarczyk at The Hardball Times noted that the home-run "factor" for the park in Arizona was 48 in one season and 116 in the next. Back in 2001, Rich Rifkin at Baseball Prospectus remarked that "Unfortunately, it is problematic to average out a park factor over more than a few years because the conditions of one or more of the ballparks in a league change. New stadiums are built, existing stadiums change their dimensions, and abnormal weather patterns have an impact." (Regrettably, the next sentence was "Nonetheless, a 10-year sample is likely to be more accurate than a one-year accounting.") Probably the defining essay on the subject is the 2007 paper titled "Improving Major League Baseball Park Factor Estimates", by Acharya, Ahmed, D'Amour, Lu, Morris, Oglevee, Peterson, and Swift, published in the Harvard Sports Analysis Collective. But, justifiably proud as they are of their improved methodology, even they concluded that "Unfortunately, the lack of longer-term data in Major League Baseball . . . makes it extraordinarily difficult to assess the true contribution of a ballpark to a team's offense or defensive strength."
Precisely accurate.
Eric Walker has been a professional baseball analyst for over a quarter-century. His paper "Winning Baseball", commissioned by the Oakland A's for the purpose, first instructed Billy Beane in the concepts later called "Moneyball"; Walker has also authored a book of essays, The Sinister First Baseman and Other Observations. Walker is now retired, but maintains the HBH Baseball-Analysis Web Site.
Comments
Regrettably, the next sentence was "Nonetheless, a 10-year sample is likely to be more accurate than a one-year accounting."
Isn't this true, though? Given that the error in single season park factors is so large, wouldn't a 10 year sample be more accurate than a 1 year sample?
Posted by: jeremy at April 16, 2009 8:34 PM
Jeremy,
10-year sample should reduce random error, that's what increase in sample-size is for. But if the increase in sample-size introduces systematic error, resulting error can be larger than 1-year sample. For example, when Royals pulled fences in, they made their park more hitter-friendly, and every other park in the league more pitcher-friendly. Any data set that has data from both old and new configuration will introduce systematic error in the calculation and for AL Central stadiums that error may be larger than random error of 1-year sample.
Posted by: DR at April 17, 2009 3:31 AM
Eric,
First off, great work. Park factors have bothered me for a long time, and you articulating what I did not have the patience nor the math skills to do.
My big question becomes where precision and diminishing returns meet. As you suggest, we know directionally from different park factor methods that Petco supresses runs and Coors increases them. The question becoems, in my mind, is how precise do we need to be for the information to be useful? And at what point are we chasing a statistical 'over-engineered' measure? Or better put, how precise do we need to be to get better analysis?
Posted by: Adam at April 17, 2009 1:33 PM
First, yes, the point is that the changes from year to year in parks--structural changes of consequence to performance or, often, entirely new parks--makes multi-year data even worse than one-year data. Remember again that it is not only the stability of Park X that matters, but also the stability of the pool we are comparing it to, that imaginary all-average ballpark; when that changes significantly, as it does virtually every year, it renders multi-year data worthless for comparisons.
Second, and related, my belief, which I think the rows and columns of the big table bear out, is that we simply cannot with any shred of honesty apply numerical park corrections to any statistic. To multiply, say, runs by 1.05 is dishonest if we know that the correct figure might be, say, anywhere from 0.85 to 1.25 (and the true range is probably worse).
I believe--I assure you, with much regret, that we just have to bite the bullet and be more qualitative than quantitative: yes, those are Colorado results, so take them with a handful of salt--that sort of thing. We all love hard numbers, but park factors are very soft, squishy numbers.
Posted by: Eric Walker at April 17, 2009 4:03 PM
Eric,
Thanks for the mention and the kind words. Subtle distinction - our paper was published in The Journal of Quantitative Analysis in Sports and presented at The New England Symposium on Statistics in Sports. The Harvard Sports Analysis Collective is the student group.
Posted by: Bobby Swift at April 18, 2009 9:46 AM
While the "primer" by Eric is instructive and caution should always be taken when adjusting team or player stats using PF's...
There are several problems with his thesis:
First of all, all of the issues he speaks of can be handled, statistically, with no problem whatsoever, if one has the know-how and takes the time to do so. So let us not throw the baby out with the bath water by declaring that "All PF's are next to worthless, don't work, cannot and should not be used to adjust player and team stats, etc."
More importantly, even a "bad" park factor can be useful and can be used appropriately.
In fact, consider this statement by Eric:
"The end results are not totally meaningless: we can say with fair credibility that San Diego's is a considerably more pitcher-friendly park than Colorado's, and that the Mets and the Marlins were playing in parks without gross distorting effects. But to try to numerically correct any team's results--much less any particular player's results--by means of "park factors" is very, very wrong."
He is 100% correct in the first part. That obviously there is SOMETHING even in "bad" park factors that is able to give us useful information. Even a "bad" PF generally tells us that COL is more of a hitter's park than SD or WAS and that TEX is more of a hitter's park than OAK. So there must be SOME good information in PF's, which there is of course. It is good information combined with noise (and perhaps some biases).
The last part of his statement is flat out wrong, considering the first part. If the first part is correct, which it is - that even a sloppy PF gives us some useful information, then it HAS to be correct that we can use those PF's to adjust player and team stats so that or adjusted stats more accurately reflect a player or team's performance in a park neutral environment. HAS TO!
That does not mean, however, that we have to use a "bad" park factor as the purveyor of that PF wants us to use it. For example, let's say that our "bad" PF tells us that Coors inflates runs (as compared to the whole league) by 20% and that Petco deflates it by 10%. Even Eric would agree that while he does not trust those numbers exactly, that they probably are on the right track and are somewhat in the ballpark, no pun intended.
But he, and other "PF naysayers" don't want us to use those PF's to adjust player and team stats, apparently, at least according to the last part of the statement from him I quoted above.
Poppycock!
Would it be better to, say, take a run scored in Coors (by some team, player, or whatever) and do nothing or would it be better to say, adjust it by 1% (even though our "bad" PF says to adjust it by 20%)? If you said, "Better to adjust (by 1%) then not adjust at all, you would be correct!"
What about Petco and adjusting by 1% versus not adjusting at all? Same answer. I hope everyone gets my point so far.
So, it is not that these "bad" PF's are not useful, it is that it is not necessarily correct to use the exact numerical adjustments that the purveyors of these PF's might want you to use - for example 20% for Coors and 10% for Petco.
So the answer is not to "not use them at all" which is (incorrectly) throwing the baby out with the bathwater. The answer is for YOU to figure out how much of the actual PF that some system comes up with to use. You do that by evaluating the rigor of the system and how much data it uses. For example, there is absolutely NO reason not to use, for example, at least half of a run factor derived from a system that takes into consideration each team's schedule and year to year changes in parks and uses 10 years worth of data. (And by the way, using 10 years of data in just about any PF "system" is going to yield a number that is more accurate than the same system using 1 year numbers almost no matter what, and it is not going to even be close, as long as that system is halfway decent).
Getting back to the Coors and Petco example above and the "bad" (but still reasonable, like the ESPN one) PF system that gives Coors a 120 rating and Petco a 90 rating, so if most of us are in agreement that it would still be correct to adjust Coors and Petco numbers by 1% (in opposite directions of course), then what about 2%? How about 5%?
Where do we cross the line from improving our numbers (by doing SOME adjustments) to doing worse than nothing at all? I don't know the answer to that as it depends on, as I said, how the particular system is constructed (is it a good one or not), but I can tell you that for almost any halfway decent system you can always use a little bit of a park factor to neutralize performance and do better than nothing at all. And even if 120 and 90 are not correct, it STILL might be better to use the entire numbers than do nothing at all!
Let's say that the real numbers are 115 and 95, which would not be unreasonable for a system that gets 120 and 90 (there is always going to be regression towards 100). Do you think using 90 and 120 to adjust player and team numbers would be better or worse than using nothing at all? Again, if you said better, you would be correct!
Posted by: MGL at April 20, 2009 1:43 AM
I just cannot grasp how arguments like this can be advanced. You cannot make a silk purse out of a sow's ear of inadequate data. If I have raw data, say runs per game, that are exactly equal for two different parks, and I then "adjust" those data by park factors (calculated I don't give a flying wahoo how), I might get, say +10% for one and -5% for the other--when, as the table data show, the reality could as well be more or less exactly the opposite. I don't know how loudly I can shout it, but WE CANNOT KNOW. You cannot extract conclusions from grossly inadequate sample sizes, and no magic can change that. To paraphrase Gertrude Stein, Inadequate data is inadequate data is inadequate data. For example, half of the attempts to get merely a runs factor for a park as extreme as Colorado is thought to be show it as less than 1. Even restricting ourselves to only the other teams in the same division still shows one value well under 1. All told, sure, Colorado is pretty surely a hitter's park, as common experience suggests, but to dream that we know well enough how much of one--even in this extreme case--to have the nerve to "adjust" data is farcical.
The claim that "'PF naysayers' don't want us to use those PF's to adjust player and team stats" is a half-truth: I, at least, would love to have park factors usable to adjust obviously biased data, and for years--back when new parks were unusual occurrences and structural changes in older ones not common--I calculated and used them. But I indeed do not myself today use "those PF's", nor would I put much trust in any who do, because such PFs are not numbers, they are doodles, about as like to make the errors worse than better while yet presenting those diddled results as if they are some sort of improvement on the historical raw originals. Till MLB issues a flat 10-year ban on all new parks and structural changes to extant ones (standard advice about repressed respiration), meaningful park factors will remain a pipe dream.
This is not religion, where you pick a doctrine to believe in because it appeals to you: it is numerical analysis, and if someone knows a method for getting meaningful measures from meaningless sample sizes, I'd be pleased to hear of it.
Posted by: Eric Walker at April 20, 2009 2:48 AM
MGL is correct that something is better than nothing. He is also correct that if you use too much, it might be worse than using nothing.
Take the case of Barry Bonds. He has had substantial playing time at SF's home park. The number of HR he hit at home and on the road in his SF years are virtually identical. But, if you look at all other LHH, you will find that SF depresses HR by 33%.
If you look at Juan Pierre at Coors, you will find that his HR rate does not change. If you look at Dante Bichette, you will see that it changes substantially.
The real danger is using a one-size-fits-all park impact number, when each player is unique. In the case of Bonds and Pierre, no park impact number is better than using any. In the case of Bichette, you come to the opposite conclusion.
The real position to take is that current park impact numbers gets you from step A to some intermediate step, when we still have to get to step Z. Some people believe that that intermediate step is step B or C, and others believe it's step X or Y.
Posted by: tangotiger at April 20, 2009 7:19 AM
I mean Barry's latest SF home park, which has been known as Pac Bell, SBC and now AT&T.
Posted by: tangotiger at April 20, 2009 7:23 AM
"For example, half of the attempts to get merely a runs factor for a park as extreme as Colorado is thought to be show it as less than 1."
If you break down a sample into small enough pieces, won't things always appear quirky? Why not take the team vs. team route to the extreme: compare one home game to one away game for each team-team pair? Holy noise!
What we really care about are the error bars on a PF. In the article, Eric claims they could be larger than +/- .20. I doubt they're that large, once you use multiple seasons worth of data and properly regress. Anyone else who's looked at PFs care to show what errors bars we can expect?
Posted by: Sky at April 20, 2009 8:08 AM
Eric is right that they could get pretty large if you are using it on individual players (which is REALLY what we ultimately care about).
No one is going to convince me that Pac Bell has had a depressing effect on Bonds' HR total anywhere close to the 33% drop other LHH have suffered there. Indeed, it would be fairly difficult to convince anyone that it's had anything more than a smidge of an effect on Bonds himself.
The uncertainty level of a park impact to each hitter will be fairly large. That's not to say that you should do an adjustment. But, if you decide to realign Bonds using all other LHH hitters, you will need to add 50% to his home HR totals (if you use a multiplier) or +.01 per home PA (if you use the additive method). Or somewhere in-between if you use the Odds Ratio Method.
Posted by: tangotiger at April 20, 2009 8:48 AM
Eric,
If your point is that the ESPN numbers are not perfectly accurate, I agree with you.
How accurate do you think they are? Saying that they're "comically insufficient" may be true, but that statement is not useful unless it's quantitative. In numerical terms, how useful or accurate are they? Are you saying that the 95% confidence intervals for parks are so wide that they all embrace 1.000? Are you saying they're even wider?
Can you be a little more quantitatively precise so that we can evaluate your claim?
Posted by: Phil Birnbaum at April 20, 2009 9:05 AM
(Sorry for the delay: I've been--and still am--running a mild fever, and not been up to doing much.)
I think at this point that rather than try to answer a potentially endless series of "but what about/but what if" queries, I'd like to see the thing turned around. If meaningful park factors can be derived, let's have someone present the methodology and actually do it, using real-world numbers. Take into account not only the several things already mentioned, but these, too: most or all parks are, at least anecdotally, held to play nontrivially differently at night versus in the day, so either demonstrate that that is not so or show how the distinction is normalized out; ditto for handedness of pitchers; ditto for stadia with retractable roofs. (Other matters may also occur to you.)
As a criterion for "meaningful", imagine that you are employed by a team that could sign either, but not both, of two players who each have an established history at some park, but not the same park, and who have essentially identical raw stats, and whose GM asks you, his house wizard, which is the better hitter. On your answer, which you propose to obtain by applying your park factors, may ride several million dollars of the team's money, the team's record over the next season or three, and certainly rides your prospects for continued employment by that team and possibly in the industry. Park factors that you would feel happy using in that case--that you are confident will not mistakenly identify which is the better man--are what are wanted.
Posted by: Eric Walker at April 22, 2009 11:21 PM